Android 进阶之性能优化 代码级优化
缓存
缓存已经计算好的数据,避免不必要的重复计算。
Batching
Batching是在真正执行运算操作之前对数据进行批量预处理,例如你需要有这样一个方法,它的作用是查找某个值是否存在与于一堆数据中。假设一个前提,我们会先对数据做排序,然后使用二分查找法来判断值是否存在。我们先看第一种情况,下图中存在着多次重复的排序操作。
在上面的那种写法下,如果数据的量级并不大的话,应该还可以接受,可是如果数据集非常大,就会有严重的效率问题。那么我们看下改进的写法,把排序的操作打包绑定只执行一次: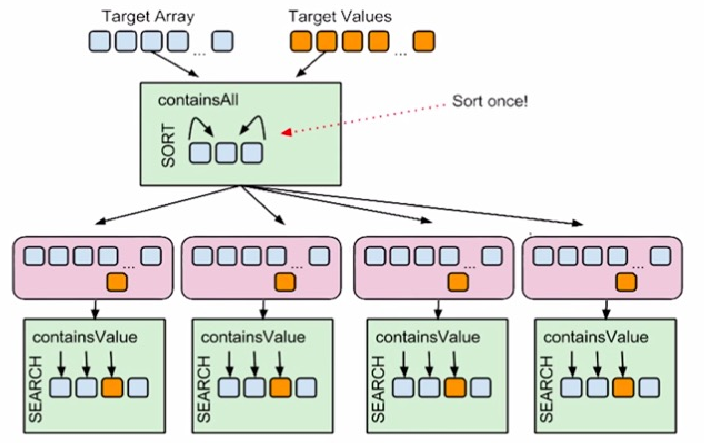
上面就是Batching的一种示例:把重复的操作拎出来,打包只执行一次。
逐步过滤筛选 ,减小搜索的数据集
对于需要在大量数据集中获取某个数据的时候通过逐步对数据进行过滤筛选,减小搜索的数据集, 可以十分明显地提高程序的执行性能。
多线程
使用多线程并发处理任务,从某种程度上可以快速提高程序的执行性能。对于Android程序来说,主线程通常也成为UI线程,需要处理UI的渲染, 响应用户的操作等等。对于那些可能影响到UI线程的任务都需要特别留意是否有必要放到其他的线程来进行处理。如果处理不当,很有可能引起程序ANR。
遍历器的选用:
在Android上可能用到的三种不同的遍历方法: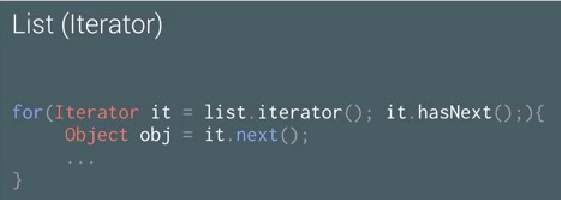
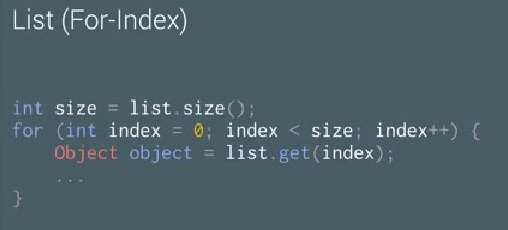

使用上面三种方式在同一台手机上,使用相同的数据集做测试,他们的表现性能如下所示:
从上面可以看到for index的方式有更好的效率,但是因为不同平台编译器优化各有差异,我们最好还是针对实际的方法做一下简单的测量比较好,拿到数据之后,再选择效率最高的那个方式。
借助Lint工具优化代码
Lint是Android提供的一个静态扫描应用源码并找出其中的潜在问题的一个强大的工具。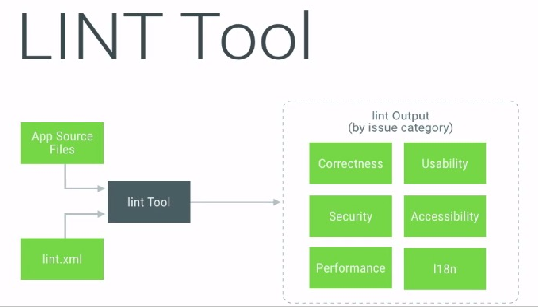
Lint的功能非常强大,它能够扫描各种问题。当然我们可以通过Android Studio设置找到Lint,对Lint做一些定制化扫描的设置,可以选择忽略掉那些不想Lint去扫描的选项,我们还可以针对部分扫描内容修改它的提示优先级。
借助Strict Mode 进行代码优化
Android提供了一个叫做Strict Mode的工具,我们可以通过手机设置里面的开发者选项,打开Strict Mode选项,如果程序存在潜在的隐患,屏幕就会闪现红色。我们也可以通过StrictMode API在代码层面做细化的跟踪,
避免在主线程做访问网络,IO读写等耗时操作。
避免创建不必要的对象
如果你需要返回一个String对象,并且你知道它最终会需要连接到一个StringBuffer,请修改你的函数实现方式,避免直接进行连接操作,应该采用创建一个临时对象来做字符串的拼接这个操作。
当从已经存在的数据集中抽取出String的时候,尝试返回原数据的substring对象,而不是创建一个重复的对象。使用substring的方式,你将会得到一个新的String对象,但是这个string对象是和原string共享内部char[]空间的。
选择Static而不是Virtual
如果你不需要访问一个对象的值,请保证这个方法是static类型的,这样方法调用将快15%-20%。
常量声明为Static Final
考虑下面这种声明的方式
static int intVal = 42; |
编译器会使用一个初始化类的函数,然后当类第一次被使用的时候执行。这个函数将42存入intVal,还从class文件的常量表中提取了strVal的引用。当之后使用intVal或strVal的时候,他们会直接被查询到。
我们可以用final关键字来优化:
static final int intVal = 42; |
这时再也不需要上面的方法了,因为final声明的常量进入了静态dex文件的域初始化部分。调用intVal的代码会直接使用42,调用strVal的代码也会使用一个相对廉价的“字符串常量”指令,而不是查表。
避免内部的Getters/Setters
在面向对象编程中,将getter和setting暴露给公用接口是合理的,但在类内部应该仅仅使用域直接访问。
在没有JIT(Just In Time Compiler)时,直接访问变量的速度是调用getter的3倍。有JIT时,直接访问变量的速度是通过getter访问的7倍。
使用包级访问而不是内部类的私有访问
参考下面一段代码
public class Foo { |
这里重要的是,我们定义了一个私有的内部类Foo$Inner,它直接访问了外部类中的私有方法以及私有成员对象。这是合法的,这段代码也会如同预期一样打印出
Value is 27。 |
问题是,VM因为Foo和Foo$Inner是不同的类,会认为在Foo$Inner中直接访问Foo类的私有成员是不合法的。即使Java语言允许内部类访问外部类的私有成员。为了去除这种差异,编译器会产生一些仿造函数:
/*package*/ |
每当内部类需要访问外部类中的mValue成员或需要调用doStuff()函数时,它都会调用这些静态方法。这意味着,上面的代码可以归结为,通 过accessor函数来访问成员变量。早些时候我们说过,通过accessor会比直接访问域要慢。所以,这是一个特定语言用法造成性能降低的例子。
如果你正在性能热区(hotspot:高频率、重复执行的代码段)使用像这样的代码,你可以把内部类需要访问的域和方法声明为包级访问,而不是私有访问权限。不幸的是,这意味着在相同包中的其他类也可以直接访问这些域,所以在公开的API中你不能这样做。
避免使用float类型
Android系统中float类型的数据存取速度是int类型的一半,尽量优先采用int类型。
使用库函数
除了那些常见的让你多使用自带库函数的理由以外,记得系统函数有时可以替代第三方库,并且还有汇编级别的优化,他们通常比带有JIT的Java编译出来的代码更高效。典型的例子是:Android API 中的 String.indexOf(),Dalvik出于内联性能考虑将其替换。同样 System.arraycopy()函数也被替换,这样的性能在Nexus One测试,比手写的for循环并使用JIT还快9倍。
谨慎使用native函数
结合Android NDK使用native代码开发,并不总是比Java直接开发的效率更好的。Java转native代码是有代价的,而且JIT不能在这种情况下做优化。 如果你在native代码中分配资源(比如native堆上的内存,文件描述符等等),这会对收集这些资源造成巨大的困难。你同时也需要为各种架构重新编 译代码,甚至对已同样架构的设备都需要编译多个版本
使用更加轻量的数据结构
利用Android 系统中专门优化过的容器类,例如SparseArray, SparseBooleanArray, 与 LongSparseArray。 通常的HashMap的实现方式更加消耗内存,因为它需要一个额外的实例对象来记录Mapping操作。另外,SparseArray更加高效在于他们避免了对key与value的autobox自动装箱,并且避免了装箱后的解箱。
避免在Android里面使用Enum
Enums的内存消耗通常是static constants的2倍。应该尽量避免在Android上使用enums。
适当的代码抽象,但是不要过分的抽象。
资源管理部分优化
- 不要存在重复的代码和无用的代码,移除不用的库
- 如果需要使用到的功能仅仅是某个库的极小部分可以尝试移植这个库或者自己实现而不是将整个库导入。
- 使用proguard混淆代码,它会对不用的代码做优化,并且混淆后也能够减少安装包的大小。
- native code的部分,大多数情况下只需要支持armabi与x86的架构即可。如果非必须,可以考虑拿掉x86的部分。
- 使用Lint工具查找没有使用到的资源。去除不使用的图片,String,XML等等。
- assets目录下的资源请确保没有用不上的文件。
- 生成APK的时候,aapt工具本身会对png做优化,但是在此之前还可以使用其他工具如tinypng对图片进行进一步的压缩预处理。
- jpeg还是png,根据需要做选择,在某些时候jpeg可以减少图片的体积,还可以选择wabp格式。
- 对于9.png的图片,可拉伸区域尽量切小,另外可以通过使用9.png拉伸达到大图效果的时候尽量不要使用整张大图。
- 有选择性的提供hdpi,xhdpi,xxhdpi的图片资源。建议优先提供xhdpi的图片,对于mdpi,ldpi与xxxhdpi根据需要提供有差异的部分即可。
- 尽可能的重用已有的图片资源。例如对称的图片,只需要提供一张,另外一张图片可以通过代码旋转的方式实现。
- 能用代码绘制实现的功能,尽量不要使用大量的图片。例如减少使用多张图片组成animate-list的AnimationDrawable
