Android 进阶之第三方库的介绍 Fresco

在学习Glide的时候发现有篇非常好的博客
Introduction to Glide, Image Loader Library for Android, recommended by Google
正想对其进行翻译发现,已经有现成的了,所以就直接转过来和大家一起分享:
本文转自Google推荐的图片加载库Glide介绍
在泰国举行的谷歌开发者论坛上,谷歌为我们介绍了一个名叫 Glide 的图片加载库,作者是bumptech。这个库被广泛的运用在google的开源项目中,包括2014年google I/O大会上发布的官方app。
毫无疑问,这个库引起了我的兴趣。于是我花了一个晚上研究和把玩它,将它的实现原理分析清楚以后,我决定写一篇博文分享一些自己的经验。在开始之前我想说,Glide和Picasso有90%的相似度,准确的说,我觉得它就像 Picasso 的克隆体。不管怎样,Glide 和 Picasso在细节上还是有不少区别的,接下来我会让你们了解到其中的差异。
Picasso和Glide都在jcenter上。在项目中添加依赖非常简单:
dependencies { |
dependencies { |
就如我所说的Glide和Picasso非常相似,Glide加载图片的方法和Picasso如出一辙。
Picasso
Picasso.with(context) |
Glide
Glide.with(context) |
虽然两者看起来非常相似,但是 Glide 的代码无疑设计得更好,因为 Glide 的 with() 方法不光接受 Context,还接受 Activity 和 Fragment。此外,with() 方法还能自动地从你放入的各种东西里面提取出 Context,供它自己使用。
同时将Activity/Fragment作为with()参数的好处是:图片加载会和Activity/Fragment的生命周期保持一致,比如 Paused状态在暂停加载,在Resumed的时候又自动重新加载。所以我建议传参的时候传递Activity 和 Fragment给Glide,而不是Context。
下面是加载图片时和Picasso的比较(1920x1080 像素的图片加载到768x432的ImageView中)
可以看到Glide加载的图片质量要差于Picasso(ps:我看不出来哈),为什么?这是因为Glide默认的Bitmap格式是RGB_565 ,比ARGB_8888格式的内存开销要小一半。下面是Picasso在ARGB8888下与Glide在RGB565下的内存开销图(应用自身占用了8m,因此以8为基准线比较):
如果你觉得 Glide 在默认的 RGB_565 格式下加载的图片质量可以接受的话,可以什么都不做。但如果你觉得难以接受,或者是你的实际需求对图片的质量有更高的要求的话,你可以像下面的代码那样创建一个 GlideModule 子类,把 Bitmap 的格式转换到 ARGB_8888:
public class GlideConfiguration implements GlideModule { |
然后在AndroidManifest.xml中将GlideModule定义为meta-data
<meta-data android:name="com.inthecheesefactory.lab.glidepicasso.GlideConfiguration" |
这样看起来就会好很多。
我们再来看看内存开销图,虽然看起来这次 Glide 的内存开销接近于上次的两倍,但是Picasso的内存开销仍然远大于Glide。
但是上面那样做的问题在于你需要手动计算 ImageView 的尺寸,又或者是你对 ImageView 设置了具体的尺寸大小,为了解决这样的麻烦,你可以在 Picasso 中通过这样做简化你的代码:
Picasso.with(this) |
但是问题在于你需要主动计算ImageView的大小,或者说你的ImageView大小是具体的值(而不是wrap_content),你也可以这样:
Picasso.with(this) |
现在Picasso的内存开销就和Glide差不多了。
虽然内存开销差距不大,但是在这个问题上Glide完胜Picasso。因为Glide可以自动计算出任意情况下的ImageView大小。
这是将ImageView还原到真实大小时的比较。
很显然,Glide 加载的图片有些像素点变得很模糊,看起来也没有 Picasso 那么平滑。而且直到现在,我也没有找到一个可以直观改变图片大小调整算法的方法。但是这并不算什么坏事,因为很难察觉。
Picasso和Glide在磁盘缓存策略上有很大的不同。我们刚刚做了一个使用 Glide 和 Picasso 加载同一张高清图片的实验,我在实验后检查缓存目录时发现: Glide 缓存的图片和 ImageView 的尺寸相同,而 Picasso 缓存的图片和原始图片的尺寸相同。
上面提到的平滑度的问题依然存在,而且如果加载的是RGB565图片,那么缓存中的图片也是RGB565。
我尝试将ImageView调整成不同大小,但不管大小如何Picasso只缓存一个全尺寸的。Glide则不同,它会为每种大小的ImageView缓存 一次。尽管一张图片已经缓存了一次,但是假如你要在另外一个地方再次以不同尺寸显示,需要重新下载,调整成新尺寸的大小,然后将这个尺寸的也缓存起来。
具体说来就是:假如在第一个页面有一个200x200的ImageView,在第二个页面有一个100x100的ImageView,这两个ImageView本来是要显示同一张图片,却需要下载两次。
不过,你可以改变这种行为,让Glide既缓存全尺寸又缓存其他尺寸:
Glide.with(this) |
下次在任何ImageView中加载图片的时候,全尺寸的图片将从缓存中取出,重新调整大小,然后缓存。
Glide的这种方式优点是加载显示非常快。而Picasso的方式则因为需要在显示之前重新调整大小而导致一些延迟,即便你添加了这段代码来让其立即显示:
//Picasso |
Picasso 和 Glide 在磁盘缓存策略上各有所长,你应该根据自己的需求选择最合适的。对我而言,我更喜欢Glide,因为它远比Picasso快,虽然需要更大的空间来缓存。
你可以做到几乎和Picasso一样多的事情,代码也几乎一样。
Image Resizing |
正如我在博文开头所说,如果你已经熟悉如何使用 Picasso,那从Picasso转换到Glide对你来说就是小菜一碟。
Glide可以加载GIF动态图,而Picasso不能。
同时因为Glide和Activity/Fragment的生命周期是一致的,因此gif的动画也会自动的随着Activity/Fragment的状态暂停、重放。Glide 的缓存在gif这里也是一样,调整大小然后缓存。
但是从我的一次测试结果来看,用 Glide 显示动画会消耗很多内存,因此谨慎使用。
除了gif动画之外,Glide还可以将任意本地视频解码成一张静态图片。
还有一个特性是你可以配置图片显示的动画,而Picasso只有一种动画:fading in。
最后一个是可以使用thumbnail()产生一个你所加载图片的thumbnail。
其实还有一些特性,不过不是非常重要,比如将图像转换成字节数组等。 配置
有许多可以配置的选项,比如大小,缓存的磁盘位置,最大缓存空间,位图格式等等。可以在这个页面查看这些配置 Configuration 。
Picasso (v2.5.1)的大小约118kb,而Glide (v3.5.2)的大小约430kb。
不过312kb的差距并不是很重要。
Picasso和Glide的方法个数分别是840和2678个。
必须指出,对于DEX文件65535个方法的限制来说,2678是一个相当大的数字了。建议在使用Glide的时候开启ProGuard。
Glide.with(context).load(...).asBitmap() |
Glide.with(context).load(...).asGif() |
Glide.with(context).load(“视频路径“) |
Glide.with(context).load(imageUrl).thumbnail(0.6f).into(imageView) |
Glide的.toBytes()和.transcode()方法允许在后台获取、解码和转换一个图片,你可以将一张图片转换成更多有用的图片格式,比如,上传一张250*250的图片
Glide.with(context) |
.animate(ViewPropertyAnimation.Animator) |
Glide和Picasso都是非常完美的库。Glide加载图像以及磁盘缓存的方式都要优于Picasso,速度更快,并且Glide更有利于减少OutOfMemoryError的发生,GIF动画是Glide的杀手锏。不过Picasso的图片质量更高。你更喜欢哪个呢?
虽然我使用了很长时间的Picasso,但是我得承认现在我更喜欢Glide。我的建议是使用Glide,但是将Bitmap格式换成 ARGB_8888、让Glide缓存同时缓存全尺寸和改变尺寸两种。
Glide 优点:
![]()
它是一个图片的加载和缓存库,它能以最简单的方式来加载一张图片,目前最新的版本为2.5.2我们可以到如下的官网下载最新的jar包,或者在Android studio 在module build.gradle配置文件中加入如下的配置:
Picasso 官网
compile 'com.squareup.picasso:picasso:2.5.2' |
Picasso的用法十分简单,并且不仅仅能加载网络资源,也能加载本地图片,Android资源文件,以及使用URI地址对图片进行加载。
Picasso.with(context) |
但是有时候标准的Picasso对象并不能满足我们特定情形的要求,所以就需要使用 Picasso.Builder:
Picasso.Builder customPicassoBuilder = new Picasso.Builder(context); |
try{ |
ImageView imageView = (ImageView) findViewById(R.id.imageView); |
ImageView imageView = (ImageView) findViewById(R.id.imageView); |
ImageView imageView = (ImageView) findViewById(R.id.imageView); |
public View getView(int position, View convertView, ViewGroup parent) { |
ImageView imageView = (ImageView) findViewById(R.id.imageView); |
Picasso |
Picasso |
当我们对一张图片只需要进行简单的旋转处理时,只需要调用传入大于0小于360的旋转角度即可:
Picasso.with(context) |
除了上述的旋转,还可以为旋转设定一个支点,只需要将上述的rotate换作rotate(float degrees, float pivotX, float pivotY) 即可:
Picasso |
对无效Uri的响应图片:
.placeholder(R.mipmap.ic_launcher) |
对访问错误时的响应图片
.error(R.mipmap.error) |
不使用默认的淡入的效果,加载的图片直接显示在ImageView上:
Picasso |
第二次图片进来的时候不使用占位图片noPlaceholder
Picasso |
使用fit 优化减小内存空间占用
使用fit Picasso会对图片的大小及ImageView控件进行测量,计算出最佳的大小及最佳的图片质量以减少内存;
Picasso |
设置图片加载的优先级
Picasso支持设置优先级,分为HIGH, MEDIUM, 和 LOW,所有的加载默认优先级为MEDIUM,但是这种设置并不能保证图片一定会优先加载,只是会偏向于优先加载,这个和给某个变量声明为regiter是一个道理的
Picasso |
在ListView中使用网络图片是很常见的,在我们滑动ListView的时候Picasso是会不断在进行网络请求,取消请求,再次请求,取消请求的状态进行的,这往往会对性能产生严重影响。使用TAG标签,可以在用户在快速滑动的时候全部停止请求,只有在滑动停止时再去请求。
Picasso提供了三种设置Tag的方式
暂停标记 pauseTag() |
用法:
首先为某个Picasso对象添加一个标签:
Picasso |
然后实现滑动监听,在监听中操作Tag
@Override |
cancleTag() 一般在不再需要进行网络请求的时候进行调用,并且在使用TAG的时候要记住如果tag状态为pause或者resume的话,Picasso会对tag持有一个引用,如果没有及时处理当前Activity退出的时候,执行垃圾回收的时候,就会出现内存泄露,所以要注意在onDestory()方法中进行相应处理。以避免这种情况的发生。
.fetch() 不会返回Bitmap,更不会展现在ImageView上,它只是将数据加载到本地和内存中从而加快后期的加载速度。
.get() 使用get会返回一个Bitmap,但是该方法不能在主线程中调用,因为会造成线程阻塞;
.target() 上面的例子我们都是使用.into()方法,将图片资源加载到ImageView中,除了这种方法还可以使用方法来实现同样的功能:
private Target target = new Target() { |
Picasso |
使用Picasso可以将图片加载到RemoteViews上,从而可以在锁屏,Widget,以及Notification上使用Picasso。下面是对应的用法:
RemoteViews remoteViews = new RemoteViews(getPackageName(),R.layout.item_picasso); |
首先通过实现Transformation 接口来实现一个Transformation
public class BlurByPicasso implements Transformation { |
为其设置效果:
Picasso |
除了对图片进行单种处理外还可以将多个处理应用到Picasso上,这就需要用到transform(List<? extends Transformation> transformations)
````
public class TransformationOne implements Transformation {
private final Picasso picasso;
public TransformationOne(Picasso picasso) {
this.picasso = picasso;
}
@Override
public Bitmap transform(Bitmap source) {
//在这里对图片进行各种转换
return result;
}
@Override
public String key() {
return “TransformationOne”;
}
}
public class TransformationTwo implements Transformation {
private final Picasso picasso;
public TransformationTwo(Picasso picasso) {
this.picasso = picasso;
}
@Override
public Bitmap transform(Bitmap source) {
//在这里对图片进行各种转换
return result;
}
@Override
public String key() {
return “TransformationTwo”;
}
}
接下创建一个Transformation 列表,将上述的转换添加到列表上: |
Picasso
.with(context)
.load(xxxxxxxxxxxxxxxxxx)
.transform(transformations)
.into(imageView);
|
LRU缓存占应用程序可用内存的15%
本地缓存占到硬盘空间的2%但不超过50M并且不小于5M
Picasso默认开启3个线程来进行本地与网络之间的访问
Picasso加载图片顺序, 内存–>本地–>网络
* 存储策略 |
NO_CACHE - 不将图片缓存在内存中
NO_STORE - 这个适用于所加载的图片只加载一次就没用了,这种情况Picasso使用完图片就不会在内存及本地缓存了
Picasso
.with(context)
.load(xxxxxxxxxx)
.memoryPolicy(MemoryPolicy.NO_CACHE)
.into(imageView);
或者:
Picasso
.with(context)
.load(xxxxxxxxxx)
.memoryPolicy(MemoryPolicy.NO_CACHE, MemoryPolicy.NO_STORE)
.into(imageView);
|
NO_CACHE - 让Picasso跳过从本地读取资源这一过程
NO_STORE - 让Picasso不进行本地图片缓存
OFFLINE - 让Picasso加载图片的时候只从本地读取,除非联网正常并且本地找不到资源的情况下
``` |
同时memoryPolicy和networkPolicy还可以一起使用:
Picasso |
Picasso |
蓝色 - 从内存中获取,是最佳性能展示 |
Picasso |
StatsSnapshot picassosnapStats = Picasso.with(context).getSnapshot(); |

GitHub地址:https://github.com/JakeWharton/butterknife
ButterKnife文档:http://jakewharton.github.io/butterknife/
buildscript { |
添加支持lint warning 检查机制
lintOptions { |
防止与dagger-compiler冲突
packagingOptions { |
添加混淆配置
-keep class butterknife.** { *; } |
有了上述的准备工作就可以使用BufferKnife了:
很简单只需要使用@BindView后面紧跟着View的id,在onCreate方法中使用ButterKnife.bind进行绑定即可。但是需要注意的是对于绑定的成员变量不能是private,或者static的否则会出现:
@Bind fields must not be private or static. …
class ExampleActivity extends Activity { |
class ExampleActivity extends Activity { |
public class FancyFragment extends Fragment { |
public class MyAdapter extends BaseAdapter { |
单击事件绑定:
|
多个View也可以绑定到一个处理方法上:
@OnClick({ R.id.door1, R.id.door2, R.id.door3 }) |
对于自定义的View,可以直接绑定到他的处理方法上而不需要指定ID
public class FancyButton extends Button { |
我们可能需要在Fragment销毁的时候将绑定的View全部设置为null,ButterKnife提供了一个unbind方法自动执行这个操作。
public class FancyFragment extends Fragment { |
默认情况下对于使用 @Bind绑定View或者使用onClick绑定事件的时候这个View都必须存在,如果不存在将会抛出错误,但是我们有可能会遇到Target View不存在的情况,这时候就需要用到@Nullable 和@Optional 了,其中前者用于修饰成员变量,后者用于修饰方法。
@Nullable @BindView(R.id.might_not_be_there) TextView mightNotBeThere; |
如果我们有一系列的View放到了一个List里面,就可以进行批量操作了:批量绑定,批量设置属性等。
@BindViews({ R.id.first_name, R.id.middle_name, R.id.last_name }) |
使用apply方法可以允许将Action立刻应用到View list 上。
ButterKnife.apply(nameViews, DISABLE); |
下面是对应的Setter以及Action的定义:
static final ButterKnife.Action<View> DISABLE = new ButterKnife.Action<View>() { |
apply方法还可以用于将Android 属性应用到View数组中:
ButterKnife.apply(nameViews, View.ALPHA, 0.0f); |
缓存已经计算好的数据,避免不必要的重复计算。
Batching是在真正执行运算操作之前对数据进行批量预处理,例如你需要有这样一个方法,它的作用是查找某个值是否存在与于一堆数据中。假设一个前提,我们会先对数据做排序,然后使用二分查找法来判断值是否存在。我们先看第一种情况,下图中存在着多次重复的排序操作。
在上面的那种写法下,如果数据的量级并不大的话,应该还可以接受,可是如果数据集非常大,就会有严重的效率问题。那么我们看下改进的写法,把排序的操作打包绑定只执行一次: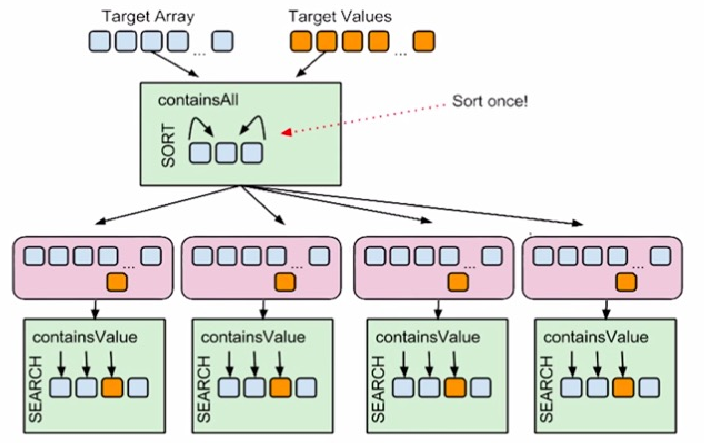
上面就是Batching的一种示例:把重复的操作拎出来,打包只执行一次。
对于需要在大量数据集中获取某个数据的时候通过逐步对数据进行过滤筛选,减小搜索的数据集, 可以十分明显地提高程序的执行性能。
使用多线程并发处理任务,从某种程度上可以快速提高程序的执行性能。对于Android程序来说,主线程通常也成为UI线程,需要处理UI的渲染, 响应用户的操作等等。对于那些可能影响到UI线程的任务都需要特别留意是否有必要放到其他的线程来进行处理。如果处理不当,很有可能引起程序ANR。
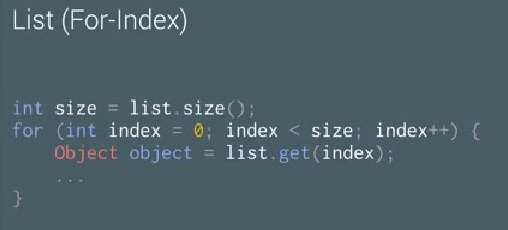
在Android上可能用到的三种不同的遍历方法: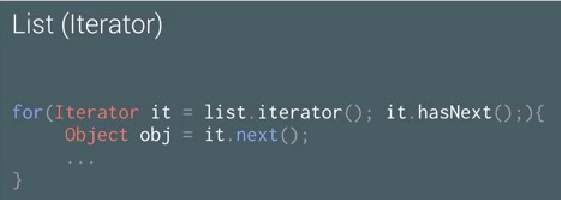

使用上面三种方式在同一台手机上,使用相同的数据集做测试,他们的表现性能如下所示:
从上面可以看到for index的方式有更好的效率,但是因为不同平台编译器优化各有差异,我们最好还是针对实际的方法做一下简单的测量比较好,拿到数据之后,再选择效率最高的那个方式。
Lint是Android提供的一个静态扫描应用源码并找出其中的潜在问题的一个强大的工具。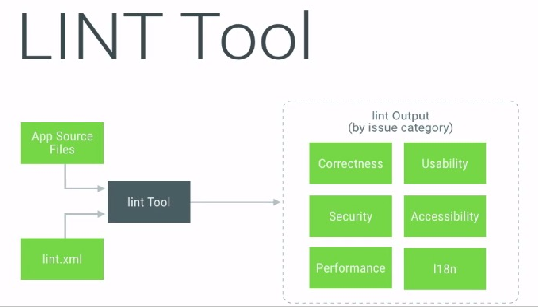
Lint的功能非常强大,它能够扫描各种问题。当然我们可以通过Android Studio设置找到Lint,对Lint做一些定制化扫描的设置,可以选择忽略掉那些不想Lint去扫描的选项,我们还可以针对部分扫描内容修改它的提示优先级。
Android提供了一个叫做Strict Mode的工具,我们可以通过手机设置里面的开发者选项,打开Strict Mode选项,如果程序存在潜在的隐患,屏幕就会闪现红色。我们也可以通过StrictMode API在代码层面做细化的跟踪,
如果你需要返回一个String对象,并且你知道它最终会需要连接到一个StringBuffer,请修改你的函数实现方式,避免直接进行连接操作,应该采用创建一个临时对象来做字符串的拼接这个操作。
当从已经存在的数据集中抽取出String的时候,尝试返回原数据的substring对象,而不是创建一个重复的对象。使用substring的方式,你将会得到一个新的String对象,但是这个string对象是和原string共享内部char[]空间的。
如果你不需要访问一个对象的值,请保证这个方法是static类型的,这样方法调用将快15%-20%。
考虑下面这种声明的方式
static int intVal = 42; |
编译器会使用一个初始化类的函数,然后当类第一次被使用的时候执行。这个函数将42存入intVal,还从class文件的常量表中提取了strVal的引用。当之后使用intVal或strVal的时候,他们会直接被查询到。
我们可以用final关键字来优化:
static final int intVal = 42; |
这时再也不需要上面的方法了,因为final声明的常量进入了静态dex文件的域初始化部分。调用intVal的代码会直接使用42,调用strVal的代码也会使用一个相对廉价的“字符串常量”指令,而不是查表。
在面向对象编程中,将getter和setting暴露给公用接口是合理的,但在类内部应该仅仅使用域直接访问。
在没有JIT(Just In Time Compiler)时,直接访问变量的速度是调用getter的3倍。有JIT时,直接访问变量的速度是通过getter访问的7倍。
参考下面一段代码
public class Foo { |
这里重要的是,我们定义了一个私有的内部类Foo$Inner,它直接访问了外部类中的私有方法以及私有成员对象。这是合法的,这段代码也会如同预期一样打印出
Value is 27。 |
问题是,VM因为Foo和Foo$Inner是不同的类,会认为在Foo$Inner中直接访问Foo类的私有成员是不合法的。即使Java语言允许内部类访问外部类的私有成员。为了去除这种差异,编译器会产生一些仿造函数:
/*package*/ |
每当内部类需要访问外部类中的mValue成员或需要调用doStuff()函数时,它都会调用这些静态方法。这意味着,上面的代码可以归结为,通 过accessor函数来访问成员变量。早些时候我们说过,通过accessor会比直接访问域要慢。所以,这是一个特定语言用法造成性能降低的例子。
如果你正在性能热区(hotspot:高频率、重复执行的代码段)使用像这样的代码,你可以把内部类需要访问的域和方法声明为包级访问,而不是私有访问权限。不幸的是,这意味着在相同包中的其他类也可以直接访问这些域,所以在公开的API中你不能这样做。
Android系统中float类型的数据存取速度是int类型的一半,尽量优先采用int类型。
除了那些常见的让你多使用自带库函数的理由以外,记得系统函数有时可以替代第三方库,并且还有汇编级别的优化,他们通常比带有JIT的Java编译出来的代码更高效。典型的例子是:Android API 中的 String.indexOf(),Dalvik出于内联性能考虑将其替换。同样 System.arraycopy()函数也被替换,这样的性能在Nexus One测试,比手写的for循环并使用JIT还快9倍。
结合Android NDK使用native代码开发,并不总是比Java直接开发的效率更好的。Java转native代码是有代价的,而且JIT不能在这种情况下做优化。 如果你在native代码中分配资源(比如native堆上的内存,文件描述符等等),这会对收集这些资源造成巨大的困难。你同时也需要为各种架构重新编 译代码,甚至对已同样架构的设备都需要编译多个版本
利用Android 系统中专门优化过的容器类,例如SparseArray, SparseBooleanArray, 与 LongSparseArray。 通常的HashMap的实现方式更加消耗内存,因为它需要一个额外的实例对象来记录Mapping操作。另外,SparseArray更加高效在于他们避免了对key与value的autobox自动装箱,并且避免了装箱后的解箱。
Enums的内存消耗通常是static constants的2倍。应该尽量避免在Android上使用enums。
适当的代码抽象,但是不要过分的抽象。
我们对移动设备网络的需求无非快速,节省流量,节省电量。
一般而言:
快速可以通过缓存方式来实现;
节省流量可以通过缓存,压缩数据源等方式;
节省耗电量 可以通过批量操作,减少唤醒电源和电源持续时间来达到,本篇博文就是尝试从这几个方面对网络优化进行介绍:
从网络上获取数据和从本地获取数据的速度差别是很大的,因此如果要提高获取数据的速度就必须尽量避免从网络上获取数据,对那些经常使用的网络数据要做好及时的缓存,以便加快访问的速度。
Android系统上HttpResponseCache是默认关闭的,这样会导致每次即使请求的数据内容是一样的也会需要重复被调用执行。我们可以通过下面的代码示例开启HttpResponseCache。
开启Http Response Cache之后,Http操作相关的返回数据就会缓存到文件系统上,不仅仅是自己编写的网络请求相关的数据会被缓存,另外引入的library库中的网络相关的请求数据也会被缓存到这个Cache中。
对于删除缓存数据可以有如下两种方式:
第一种方式是缓存溢出的时候删除最旧最老的文件
第二种方式是通过Http返回Header中的Cache-Control字段来进行控制的。如下图所示:
通常来说,HttpResponseCache会缓存所有的返回信息,包括实际的数据与Header的部分.一般情况下,这个Cache会自动根据协议返回Cache-Control的 内容与当前缓存的数据量来决定哪些数据应该继续保留,哪些数据应该删除。
但是在一些极端的情况下,或者是某些特殊的网络环境导致HttpResponseCache工作异常,在这些情况下就需要我们自己来实现Http的缓存Cache。一般不推荐自己重新实现自己的网络缓存方案,目前已经有不少著名的开源框架提供了完整的方案并获得无数项目的验证。这些方案包括Volly,okHTTP,Picasso等。
对于UI界面上展现的是网络数据的情形我们可以使用文件系统,Preference,SQLite等数据存储方式将旧的数据存储起来,在下次加载的先现实给用户存储在本地的旧数据,而不是让用户看不到任何数据。

发起网络请求与接收返回数据都是比较耗电的,在网络硬件模块被激活之后,会继续保持几十秒的电量消耗,直到没有新的网络操作行为之后,才会进入休眠 状态,如果频繁发出网络请求会导致设备的无线蜂窝一直处于高消耗的状态为了避免这个问题我们可以通过预先判定那些是可能马上就会使用到的网络资源 ,或者将当前不是特别紧急的传输往后推辞,从而将多次零散的网络请求打包成一次操作,尽量避免频繁触发网络请求,提升设备的续航时间。

网络数据预取就是在还没使用之前缓存一部分数据,等到使用的时候直接使用缓存中的数据。
使用预取数据的难点在于如何判断事先获取的数据量到底是多少,如果预取的数据量偏少,那么就起不到什么效果,但是如果预取过多,又可能导致访问的时间过长。一个比较普适的规则是,在3G网络下可以预取1-5Mb的数据量,或者是按照提前预期后续1-2分钟的数据作为基线标准。在实际的操作当中,我们还需要考虑当前的网络速度来决定预取的数据量,例如在同样的时间下,4G网络可以获取到12张图片的数据,而2G 网络则只能拿到3张图片的数据。所以,我们还需要把当前的网络环境情况添加到设计预取数据量的策略当中去。判断当前设备的状态与网络情况。
最简单的延迟传输方法是通过将那些发出的网络请求,先暂存到一个PendingQueue里面,等到队列上的请求达到某个阈值的时候再触发Queue里面的网络请求。
在网络性能方面最直观的可能要算是网络延迟了,有时候我们会看到一个加载小图标一直打圈圈。会让用户觉得十分狂躁,为了解决这个问提可以通过为不同的网络状态设定不同的网络策略。
首先我们需要获取当前网络的情况:
通过上面的代码,我们可以获取到移动网络的详细子类型,例如4G(LTE),3G,如下图所示,获取到移动网络类型之后,我们可以根据当前网络的速率来调整网络请求的行为:
通常来说,我们可以把网络请求延迟划分为三档:例如把网络延迟小于60ms的划分为GOOD,大于 220ms的划分为BAD,介于两者之间的划分为OK。如果网络延迟属于GOOD的 范畴,我们就可以做更多比较激进的预取数据的操作,如果网络延迟属于BAD的范畴,我们就应该考虑把当下的网络请求操作Hold住等待网络状况恢复到 GOOD的状态再进行处理。
网络请求频率太低有可能会导致界面上无法呈现最新的数据,但是太频繁的网络请求又会导致CPU,内存,网络流量,电量等资源被持续消耗,所以在进行网络请求操作的时候一定要避免多度同步操作。
为了能够尽量的减少不必要的同步操作,我们需要遵守下面的一些规则:


为了能够减小网络传输的数据量,我们需要对传输的数据做压缩的处理,这样能够提高网络操作的性能。首先不同的网络环境,下载速度以及网络延迟是存在差异的,如下图所示:
通常来说,网络传输数据量的大小主要由两部分组成:图片与序列化的数据,那么我们需要做的就是减少这两部分的数据传输大小。
这部分在内存优化部分已经介绍过了,不同的图片格式在图片大小图片清晰度方面有较大的差异,在需要传输网络图片的时候需要选用适合的图片格式,下面是三种主流图片格式的对比。
对于JPEG与WEBP格式的图片,不同的清晰度对占用空间的大小也会产生很大的影响,适当的减少JPG Quality,可以大大的缩小图片占用的空间大小。
上述介绍的是从图片格式上选择图片资源,下面将从图片尺寸的选择上选择图片资源。
为了减小源图片的大小可以考虑为不同的使用场景提供当前场景下最合适的图片大小,例如针对全屏显示的情况我们会需要一张清晰度比较高的图片,而如果只是显示为缩略 图的形式,就只需要服务器提供一个相对清晰度低很多的图片即可。服务器应该支持到为不同的使用场景分别准备多套清晰度不一样的图片,以便在对应的场景下能 够获取到最适合自己的图片。
其次需要做的是减少序列化数据的大小。JSON与XML为了提高可读性,在文件中加入了大量的符号,空格等等字符,而这些字符对于程序来说是 没有任何意义的。我们应该使用Protocal Buffers,Nano-Proto-Buffers,FlatBuffer来减小序列化的数据的大小。
总而言之:
网络优化可以从如下几个方面入手:
1.从数据源方面优化可以通过压缩图片和序列化数据方式来降低电量和流量的损耗
2.从传输方式我们可以通过缓存数据,批量传输,调整网络请求频率等方式
要进行电量优化首先需要知道到我们的设备中有哪些耗电大户:
一般而言手机中耗电最多的模块有手机的显示屏,网络模块,GPS传感器模块,冗余的后台线程和Service。
所以总体而言我们有下优化措施:
尽量减少唤醒屏幕的次数以及持续的时间。
例如下图中有三个Apk共唤醒了三次,而如果将上述的后台任务打包延迟处理,等待一个合适的时机将这些任务一并处理,如图2所示那么手机只需要被唤醒一次,这样就节省了电量的损耗。

某些非必须立刻执行的操作可以等到手机处于充电或者电量充足的时候进行。
这里就涉及到了如何判断手机电量状态的问题:
/ |


对于传感器尽量减少刷新请求,在Activity不需要监听某些Sensor数据的时候需要尽快释放监听注册,对于Sensor的数据我们尽量做批处理,待数据累积一定次数或者某个程度的时候再进行处理并更新到UI上。
对于定位功能是一个相对来说比较耗电的操作,通常来说,我们会使用类似下面这样的代码来发出定位请求:
这里关键的是setInterval()这个方法它指的意思是每隔多长的时间获取一次位置更新,时间相隔越短, 自然花费的电量就越多,但是时间相隔太长,又无法及时获取到更新的位置信息。其中存在的一个优化点是,我们可以通过判断返回的位置信息是否相同,从而决定 设置下次的更新间隔是否增加一倍,通过这种方式可以减少电量的消耗。
除了从网络请求频率的角度来优化外还可以从定位精度角度来考虑
通过GPS定位服务相比起使用网络进行定位更加的耗电,但是精度方面也相对更加精准一些为了提供不同精度的定位需求,Android提供了下面4种不同精度与耗电量的参数给应用进行设置调用,应用只需要决 定在适当的场景下使用对应的参数就好了,通过LocationRequest.setPriority()方法传递下面的参数就好了。
对于定时任务尽量使用AlarmManager,而不是sleep或者Timer进行管理
在Android系统中为避免电量过度消耗,提供了电源唤醒锁wakeLock以及JobScheduler API。
借助电源唤醒锁Android设备可以在被闲置之后迅速进入睡眠状态。还可以在屏幕关闭的时候利用唤醒锁保持后台服务的正常运行。但是一定要保证唤醒锁在最后的时刻回到初始状态。这是使用唤醒锁时候十分关键的一点。
至于唤醒锁的使用大家可以在晚上搜索相应的用法。除了唤醒锁外还有个WakefulBroadcastReceiver
,这个我自己用得比较少,所以借助这次机会对其进行总结下:
WakefulBroadcastReceiver 会将任务交给服务的同时保证设备在此过程中不会进入休眠状态。
下面是一个WakefulBroadcastReceiver 使用的例子:
在 WakefulReceiver中通过startWakefulService()来启动WakefulService,在这个过程中WakeflBroadcastReceiver会在Service启动后将唤醒锁保持住,当Service结束之后,它会调用WakefulReceiver.completeWakefulIntent()来释放唤醒锁。
public class WakefulReceiver extends WakefulBroadcastReceiver { |
尽量使用setInexactRepeating()方法替代setRepeating()方法。当你使用setInexactRepeating()方法时,Android系统会集中多个应用的重复闹钟同步请求,并一起触发它们。这可以减少系统将设备唤醒的总次数,以此减少电量消耗。
除了使用电源唤醒锁,非精确闹钟来节省电源外,还可以通过JobScheduler API来将某些任务缓存起来推迟到某个时间或者一定条件下执行,比如想要将下载图片或者歌曲的任务安排在接入电源或者Wifi连接的情况下执行。下面是JobScheduler API的使用例子:
public class MyJobService extends JobService { |
调用:
public class MainActivity extends Activity { |
注册:
<service |
使用battery-historian来进行电量的分析:
battery-historian 的gitHub地址如下:
https://github.com/google/battery-historian
关于battery-historian2 的使用推荐看下下面的这篇文章。
http://www.jianshu.com/p/a7d9a3aec423/comments/1589962
Android系统里的Generational Heap Memory的模型是一个三级Generation的内存模型,它包括Young Generation,Old Generation,Permanent Generation三个部分。最新分配的对象会存放在Young Generation区域,当这个对象在这个区域停留的时间超过某个值的时候,会被移动到Old Generation,最后到Permanent Generation区域。三个区域对象创建速度和GC执行的速度是不一样的Young Generation最快,Old Generation次之,Permanent Generation最慢。整个结构如下图所示:

三个区域的存储空间都有一个固定的大小,当这些对象总的大小快达到阀值时,会触发GC的操作,以腾出空间来存放其他新的对象。
在Android 开发过程中主要的内存异常有内存抖动,内存泄露,内存溢出(OOM)等几种。
内存抖动就是因为在短时间内存在大量对象被创建和销毁,导致内存大小极度不稳定的情况,内存抖动可以给性能带来什么直观的感觉呢?我们知道界面卡顿一般都与CPU和GPU有关,但是内存抖动也会导致卡顿的问题,要知道这个原因首先需要明白在执行GC操作的时候,当前所有线程的任何操作都要暂停,等待GC操作完成之后,其他操作才能够继续运行。一般来说每个GC并不会占用太多时间,但是大量频繁的GC则有可能会占用帧间隔时间。导致卡顿现象。
那么为什么会出现频繁的GC现象呢?上面提到过导致GC频繁发生的原因是由于短时间内大量对象被创建,瞬间产生的大量对象会占用大量的Young Generation的内存区域很有可能导致该区域的内存达到阈值,从而触发GC。我们上面讲到GC过程中暂停当前线程的所有操作,影响到帧率,给用户照成卡顿的不好体验。
那么怎么判断是否发生内存抖动呢?从代码角度比较难以看出存在问题的代码。为了解决这个问题AS为我们提供了Memory Monitor工具通过这个工具可以很直观得看出内存抖动的现象。比如下图中在红色框图中短时间内存在着大量起伏不定的内存曲线,这表明这个时间段发生了内存抖动,需要结合代码来查看到底是那部分代码导致了这个问题。
上面的方法只是从直观的角度来判断是否发生了内存抖动,但是具体是哪里发生了内存抖动还需要其他工具进行介入收集数据。我们可以通过Allocation Tracker来完成任务,如果短时间内,同一个栈中不断进出的相同对象。这很显然发生了内存抖动,需要引起足够的重视。

内存泄漏表示的是不再用到的对象原本需要被回收的但是由于被错误引用(还有对象依旧持有这个对象)而无法被正常回收。举个常见的例子通常来说,View会保持Activity的引用,Activity同时还和其他内部对象也有可能保持引用关系。当屏幕发生旋转的时候Activity就很容易发生泄漏,这样的话里面的view也会发生泄漏。这样就导致这个对象一直留在内存当中,占用了宝贵的内存空间。显然,这会使得每级Generation的内存区域可用空间逐渐变小,GC就会更容易被触发,从而引起性能问题。要解决内存泄露的问题需要我们对代码十分熟悉,当然现在有很多第三方库可以帮我们检测内存泄露的问题,比如LeakCanary。
避免使用异步回调:
异步回调被执行的时间是不确定的,有可能在回调的时候所在的Activity已经被销毁了,这不仅很容易会引起crash还很容易发生内存泄露。比如下面的例子:
避免使用static对象:
因为static的生命周期过长,使用不当很可能导致内存泄露。
避免把View添加到没有清除机制的容器里
假如把view添加到WeakHashMap,如果没有执行清除操作,很可能会导致泄漏。
Activity的泄漏
通常来说,Activity的泄漏是内存泄漏里面最严重的问题,它占用的内存多,影响面广:
我们先来看下一个非静态内部类的一个例子:
public class MainActivity extends AppCompatActivity { |
上面这个看出问题的所在了吗?
首先我们知道 mTestClass 是一个静态变量它的生命周期是整个应用周期,但是它是一个非静态内部类,所以会持有外部类的引用,换句话说MainActivity被一个生命周期为整个应用周期的对象所持有,所以它退出后就不能被GC回收。从而导致了内存泄露。
接下来我们再来看下Handler导致的内存泄露的例子:
Handler 的不正确使用造成的内存泄漏问题是比较常见的,我们知道当Android应用程序启动时,framework会为该应用程序的主线程创建一个Looper对象。这个Looper对象包含一个简单的消息队列Message Queue,它能够循环的处理队列中的消息。这些消息都会被添加到消息队列中并被逐个处理。
这个主线程的Looper对象会伴随该应用程序的整个生命周期。当我们向这个Looper发送一个消息后所有发送到消息队列的消息Message都会拥有一个对Handler的引用,当Looper来处理消息时,会回调Handler#handleMessage(Message)方法来处理消息。那么这又有什么问题呢?
问题有两点:
我们有可能会将Handler声明为非静态的内部类,这样的话它就持有外部Activity的引用,如果使用这种Handler向Looper发送消息后如果在Activity退出后仍然没有被处理,那么Message将会保留在Looper内,由于上面所说Message持有Handler的引用,Handler由于是非静态内部类所以也会持有Activity的引用,那么这样就导致了Activity退出后,内存不能被回收,也就是内存泄露了。
下面就是一个错误引用导致的问题:
public class SampleActivity extends Activity { |
还有个问题就是如果Handler当中还需要Activity的引用呢?
为了解决这个问题我们最常用的就是使用静态内部类+弱引用来断开与外部Activity的引用关系,代码如下:
然后,当主线程里,实例化一个Handler对象后,它就会自动与主线程Looper的消息队列关联起来。所有发送到消息队列的消息Message都会拥有一个对Handler的引用,所以当Looper来处理消息时,会据此回调[Handler#handleMessage(Message)]方法来处理消息。
另外,我们知道 Handler、Message 和 MessageQueue 都是相互关联在一起的,万一 Handler 发送的 Message 尚未被处理,则该 Message 及发送它的 Handler 对象将被线程 MessageQueue 一直持有。
由于 Handler 属于 TLS(Thread Local Storage) 变量, 生命周期和 Activity 是不一致的。因此这种实现方式一般很难保证跟 View 或者 Activity 的生命周期保持一致,故很容易导致无法正确释放。
举个例子:
在该 SampleActivity 中声明了一个延迟10分钟执行的消息 Message,mLeakyHandler 将其 push 进了消息队列 MessageQueue 里。当该 Activity 被 finish() 掉时,延迟执行任务的 Message 还会继续存在于主线程中,它持有该 Activity 的 Handler 引用,所以此时 finish() 掉的 Activity 就不会被回收了从而造成内存泄漏(因 Handler 为非静态内部类,它会持有外部类的引用,在这里就是指 SampleActivity)。
修复方法:在 Activity 中避免使用非静态内部类,比如上面我们将 Handler 声明为静态的,则其存活期跟 Activity 的生命周期就无关了。同时通过弱引用的方式引入 Activity,避免直接将 Activity 作为 context 传进去,见下面代码:
public class SampleActivity extends Activity { |
除了上面的例子外在Aactivity退出之前,需要注意执行remove Handler消息队列中的Message与Runnable对象从而达到彻底的退出。
在Android系统中每个app所能够使用的堆大小是有限的,不同RAM大小的设备堆大小是不同的,一旦我们的app在超过了这个限制的情况下继续分配内存的话会引起OOM.如果你想要查询当前设备的堆大小显示可以调用getMemoryClass()来查询。它会返回一个用于表示当前应用堆大小限制的数据。如果你确定你的应用需要耗费较大的堆空间,可以通过在manifest的application标签下添加largeHeap=true的属性。但是这样做有个不好的地方是,它会使得每次GC的运行时间更长,在任务切换时,系统的性能会变得大打折扣,所以在遇到内存溢出的时候不应该只借助申请大堆栈的方式来解决,而应该从根本上节省内存的消耗。
因此防止内存溢出的问题也可以转换为如何减少内存的消耗。






但是我们如果使用GSON库来处理这个序列化的问题,不仅仅执行速度更快,内存的使用效率也更高。
除了使用GSon来进行序列化这个措施来减小内存损耗外,可以通过优化数据呈现的顺序以及结构来优化内存的损耗。通常来说,一般的数据序列化的过程如下图所示:
上面的过程,存在两个不足,第一个是重复的属性名称:
另外一个是GZIP没有办法对上面的数据进行更加有效的压缩,假如相似数据间隔了32k的数据量,这样GZIP就无法进行更加有效的压缩:
但是我们稍微改变下数据的记录方式,就可以得到占用空间更小的数据,如下图所示:

通过上述优化,有了如下的优化:
(1) 减少了重复的属性名:
(2) 使得GZIP的压缩效率更高:

节省图片资源对内存空间的占用有如下几种途径:
(1) 从图片资源本身角度可以通过减小图片尺寸,降低图片的分辨率清晰度等
在设计给到资源图片的时候,我们需要特别留意这张图片是否存在可以压缩的空间,是否可以使用一张更小的图片。尽量使用更小的图片不仅仅可以减少内存的使用,还可以避免出现大量的InflationException。假设有一张很大的图片被XML文件直接引用,很有可能在初始化视图的时候就会因为内存不足而发生InflationException。
除了在尺寸上优化图片资源外,还可以考虑选择不同的图片格式,目前主流的图片格式有PNG,JPEG,WEBP三种,三种主流格式在占用空间与图片质量之间的对比如下所示:
对于JPEG与WEBP格式的图片,不同的清晰度对占用空间的大小也会产生很大的影响,适当的减少JPG Quality,可以大大的缩小图片占用的空间大小。
另外,我们需要为不同的使用场景提供当前场景下最合适的图片大小,例如针对全屏显示的情况我们会需要一张清晰度比较高的图片,而如果只是显示为缩略 图的形式,就只需要服务器提供一个相对清晰度低很多的图片即可。服务器应该支持到为不同的使用场景分别准备多套清晰度不一样的图片,以便在对应的场景下能够获取到最适合自己的图片。
(2) 合理分配图片资源
我们知道hdpi/xhdpi/xxhdpi等等不同dpi的文件夹下的图片在不同的设备上会经过scale的处理。例如我们只在hdpi的目录下放置了一张100 x 100的图片,那么根据换算关系,xxhdpi的手机去引用那张图片就会被拉伸到200x200。需要注意到在这种情况下,内存占用是会显著提高的。对于不希望被拉伸的图片,需要放到assets或者nodpi的目录下。
(3) 同一张图片还可以通过选用不同的解码方式和格式来减少对空间的占用
在Android开发过程中最常用的图片格式有png,jpeg,webp等,在这些图片被设置到UI界面之前都需要解码过程,在进行解码的时候使用不同的解码方式对内存的损耗是有极大差别的,因此在图像质量能够满足要求的情况下,尽量选用对内存要求较小的解码方式,但是要注意的是不同的解码格式,清晰度也会存在较大差别,因此需要在二者之间做出权衡。
在Android里面可以通过下面的代码来设置解码率:
在Android开发过程中我们会发现大多数的图片资源都是PNG格式的,这很大程度上是由于PNG相比于JPEG格式能够提供更加清晰无损的图片效果,但是正如上面提到的图片对内存的消耗以及图片的清晰度是一个对立面,在选用资源的过程中需要在二者之间做一个权衡。对于对于那些使用JPEG就可以达到视觉效果的,可以考虑采用JPEG。除了上述的解决方案外,还可以考虑使用Webp格式,它是由Google推出的一种既保留png格式的优点,又能够减少图片大小的一种新型图片格式。
(4) 除了上述两种还可以通过特殊处理来达到这个目的。
比如在缩放图片的时候Android提供了现成的bitmap缩放的API createScaledBitmap(),使用这个方法返回的是一张经过缩放的图片。createScaledBitmap方法能够快速的得到一张经过缩放的图片,可是这个方法能够执行的前提是原图片需要事先加载到内存中,如果原图片过大,很可能导致OOM。
为了避免这个问题的发生我们可以考虑使用inSampleSize这个属性:
inSampleSize能够等比的缩放显示图片,同时还避免了需要先把原图加载进内存的缺点。我们会使用类似像下面一样的方法来缩放bitmap:

另外,我们还可以使用inScaled,inDensity,inTargetDensity的属性来对解码图片做处理,源码如下图所示:
如果只要获取图片的大小尺寸数据可以使用inJustDecodeBounds属性,使用这个属性去尝试解码图片,可以事先获取到图片的大小而不至于占用什么内存。如下图所示:

将Bitmap重用和对象池技术结合起来可以创建一个包含多种典型可重用bitmap的对象池,这样后续的bitmap创建都能够找到合适的“模板”去进行重用。如下图所示:
在Android系统中唯一完整释放内存的方法是释放那些你可能持有的对象的引用,当这个对象没有被任何其他对象引用的时候,它才能被GC回收。但是如果系统在其他某个地方重用某个对象的话,就会导致它不能被完全回收。
使用对象池来减少需要创建的对象。
我们在开发过程中时常会遇到短时间内需要大量对象的情况,比如一个多用户的Apk,可能在某个时间点会有多个用户注册,这就有可能需要在短时间内创建大量对象,但是短时间创建大量对象会导致内存紧张,GC过程十分耗时,还有可能照成内存抖动问题。为了避免这个问题最常用的解决方式就是使用对象池。
在使用对象池的时候当使用某个对象的时候先去对象池查询是否存在,如果不存在则创建一个对象然后加入对象池,但是我们也可以在程序刚启动的时候就事先为对象池填充一些即将要使用到的数据,这样可以在需要使用到这些对象的时候提供更快的首次加载速度,这种行为就叫做预分配。使用对象池也有不好的一面,程序员需要手动管理这些对象的分配与释放,这个极有可能造成内存泄露。为了确保所有的对象能够正确被释放,我们需要保证加入对象池的对象和其他外部对象没有互相引用的关系。
复用系统自带的资源
Android系统本身内置了很多的资源,例如字符串/颜色/图片/动画/样式以及简单布局等等,这些资源都可以在应用程序中直接引用。这样做不仅 仅可以减少应用程序的自身负重,减小APK的大小,另外还可以一定程度上减少内存的开销,复用性更好。
注意在ListView/GridView等出现大量重复子组件的视图里面对ConvertView的复用
Try catch某些大内存分配的操作
在某些情况下,我们需要事先评估那些可能发生OOM的代码,对于这些可能发生OOM的代码,加入catch机制,可以考虑在catch里面尝试一次降级的内存分配操作。例如decode bitmap的时候,catch到OOM,可以尝试把采样比例再增加一倍之后,再次尝试decode。
留意单例对象中不合理的持有
由于单例对象的生命周期和应用的生命周期相一致所以要特别注意单例中所持有的对象,如果持有的对象不合理极有可能照成内存的泄露
一般我们会在Application 类中定义一个getContext方法,这样在任何需要Application Context的时候就可以通过getContext来获得
context = getApplicationContext(); |
public class SingletonClass { |
但是有时候我们并不需要继承Application这样我们就可以通过下面的方式,直接通过getApplicationContext方法来获取。
public class SingletonClass { |
优化布局层次,减少内存消耗
越扁平化的视图布局,占用的内存就越少,效率越高。我们需要尽量保证布局足够扁平化,当使用系统提供的View无法实现足够扁平的时候考虑使用自定义View来达到目的。
如果你的应用需要使用到后台服务,要记住系统会倾向保留后台服务而一直保留服务所在的进程,并且系统没有办法把服务所占用的RAM空间让出来给其他部件,所以导致了你当前进程的运行代价很高。因此在使用服务的时候要注意两点:除非它被触发并执行一个任务,否则尽量保证其他时候service都处于停止状态;尽可能使用IntentService它会在处理完交代给它的intent任务之后尽快结束自己,不要在服务不需要的时候还让服务驻留在后台,这样极有可能照成资源浪费。
其中最主要的就是如何正确得启动和停止服务。
普通的Started Service,需要通过stopSelf()来停止Service
另外一种Bound Service,会在其他组件都unBind之后自动关闭自己
和其他系统一样Android系统也是一个多任务系统,用户可以在不同的App之间快速切换,在Android系统中为了保证后台应用能够迅速切换到前台,在应用切换到后台的时候会将其缓存到后台占用一定的内存,这样做的好处就是将当前应用从后台移动到前台的时候不用重新创建,只要从缓存中直接获取并恢复。但是在系统资源不足的时候系统会尝试从LRU 缓存清除部分进程:
当系统开始清除LRU缓存中的进程时,尽管它首先按照LRU的顺序来操作,但是它同样会考虑进程的内存使用量。因此消耗越少的进程则越容易被留下来。
onTrimMemory这个方法会在系统认为进程内存最佳释放的时间点的时候被回调,它接收一个内存级别的参数用于表示,当前处于那个内存阶段,我们可以通过传入的这个数值决定释放哪些资源onTrimMemory()的回调可以发生在Application,Activity,Fragment,Service,Content Provider。
如果我们的进程处于LRU 缓存状态则会收到如下的的回调:
TRIM_MEMORY_BACKGROUND: 系统正运行于低内存状态并且你的进程正处于LRU缓存名单中最不容易杀掉的位置。尽管你的app进程并不是处于被杀掉的高危险状态,系统可能已经开始杀掉LRU缓存中的其他进程了。你应该释放那些容易恢复的资源,以便于你的进程可以保留下来,这样当用户回退到你的app的时候才能够迅速恢复。
TRIM_MEMORY_MODERATE: 系统正运行于低内存状态并且你的进程已经已经接近LRU名单的中部位置。如果系统开始变得更加内存紧张,你的进程是有可能被杀死的。
TRIM_MEMORY_COMPLETE: 系统正运行与低内存的状态并且你的进程正处于LRU名单中最容易被杀掉的位置。你应该释放任何不影响你的app恢复状态的资源。
刚接触Android开发的时候时不时地会听到帧率,60fps这些名词,当时没放在心上但是后来在工作逐渐深入的情况下,接触到了性能优化的问题,测试有的时候会抱怨apk十分卡顿,软件项目经理看到性能测试报告后会找来说怎么占用这么多资源。这时候就需要我们针对具体情况对Apk进行性能优化了。
性能优化一般分成三步:
关于性能优化主要分成如下几类:UI渲染,内存优化,电量优化,网络优化,代码级别优化,apk资源优化。这里面有些优化还具有相互关联的关系,比如电量优化和网络优化之间存在着十分密切的关联。接下来的几篇文章将把当时学习性能优化时候的总结分享出来,如果大家想从原始的资源进行学习我这边可以推荐大家如下的资源:
UI是一个Apk的脸面,在当前看脸的时代在很大程度上决定了Apk的命运。但是当当是漂亮还不行还需要流畅,你也许会常常听到用户抱怨在执行动画或者滑动ListView的时候感知到卡顿不流畅,其实这是因为这里的操作相对复杂,容易发生丢帧的现象,从而带来卡顿的感觉。
丢帧的原因很多:
但是最根本的原因是由于复杂的布局和动画导致CPU和GPU无法在16ms时间内完成当前页面的绘制与渲染,从而导致下一帧来的时候来不及绘制导致了丢帧的问题。接下来的部分将从上述的这几个方面对UI视图渲染优化进行讲解。主要涉及如下几个关键点:
这里要求的60fps不是无故规定的,这是因为人眼与大脑之间的协作无法感知超过60fps的画面更新,所以大于60fps是没有必要的,这里有几个比较常见的帧率:12fps大概类似手动快速翻动书籍的帧率,这明显是可以感知到不够顺滑的。24fps是电影胶圈通常使用的帧率,这个速率能使得人眼感知当前的画面是连续线性的运动,但是只能足够支撑大部分电影画面需要表达的内容,还是达到顺畅的标准,一般而言低于30fps是无法顺畅表现绚丽的画面内容的,此时就需要用到60fps来达到想要的效果。
要使得帧率大于60fps就要求每个绘制任务必须要在16ms内完成,否则就会出现丢帧的现象:
下面两图分别是不丢帧的情况以及丢帧的情况:
下图的第二帧更新时间要花费24ms导致了下一帧的绘图信号来的时候当前更新还未完成导致丢帧,这样在下一帧该显示的时候依旧停留在当前帧。从而在视觉上会造成卡顿的现象。当然更新任务花费的时间越短越好,因为在主线程中除了界面更新外还有用户交互等任务需要处理。
Refresh Rate:刷新率代表了在一秒内刷新屏幕的次数,这是由硬件决定的,一般会有个范围可以调整。
Frame Rate:帧率代表了GPU在一秒内绘制操作的帧数,例如30fps,60fps。
理想的情况下两个速率应该是一致的。但是在现实情况下帧率往往小于刷新频率。在这种情况下,某些帧显示的画面内容就会与上一帧的画面相同。这也就是常说的丢帧的问题。

UI 的绘制渲染任务主要是由CPU和GPU两大组件来完成的,CPU负责包括Measure,Layout,Record,Execute的计算操作,GPU负责Rasterization。下图描述了CPU,GPU的Pileline主要的问题,解决问题的工具以及解决问题的方案。
从图上可以看出CPU负责将需要绘制的UI组件计算成Polygons,Texture,然后交给GPU,GPU对其进行快速栅格化,也就是把Button等组件进行拆分到不同的像素上。

通过GPU栅格化后最终才绘制到屏幕上,为了能够使得我们的App运行得顺畅,不丢帧,需要保证在16ms内CPU 和 GPU 完成上述的计算,绘制,渲染等全部操作。
对于布局,在进行绘制的时候Android需要在DisplayList的帮助下把XML布局文件转换成GPU能够识别并绘制的对象。DisplayList持有所有将要交给GPU绘制到屏幕上的数据信息。
在某个View第一次需要被渲染时,Display List会因此被创建,当这个View要显示到屏幕上时,我们会执行GPU的绘制指令来进行渲染。如果只是View的Property属性发生了改变(例如移动位置),我们就仅仅需要Execute Display List就够了。
但是如果View中的某些可见部分发生了变化那么就需要重新创建一个DisplayList,而不能继续使用原先的DisplayList了。
需要注意的是任何时候View中的绘制内容发生变化时,都会需要重新创建并渲染DisplayList,并将渲染后的结果更新到屏幕上。举个例子,假设某个Button的大小需要增大到目前的两倍,在增大Button大小之前,需要通过父View重新计算并摆放其他子View的位置。修改View的大小会触发整个HierarcyView的重新计算大小的操作。如果是修改View的位置则会触发HierarchView重新计算其他View的位置。如果布局很复杂,这就会很容易导致严重的性能问题。
CPU部分的问题—布局的层级太深
最理想的布局在Hierarchy View 上是呈现扁平状的,也就是布局的层级结构不能太深,不要使用太多的布局嵌套关系。这部分的优化可以使用Hierarcy Viewer进行优化。
GPU 部分的主要问题有两个方面:

但是从布局代码上很难直观得找出哪些像素块发生了Overdraw现象,如果要查看UI上的Overdraw情况可以打开Settings开发者选项的Show GPU Overdraw开关进行观察。
蓝色,淡绿,淡红,深红代表了4种不同程度的Overdraw情况,我们优化的目标就是尽量减少红色的区域。
具体的优化有如下的方案:
移除默认的Background
移除XML布局文件中非必需的Background
按需显示占位背景图片(也就是在ListView每个Item的ImageView上不事先显示占位图片,先去获取要显示的图片如果获取失败的时候再使用占位图片来显示在ImageView上)
对于复杂的自定义View由于Android系统无法检测在onDraw里面具体会执行什么操作,这就导致难以避免Overdraw。但是这个问题并不是完全没有办法解决,Android提供了canvas.clipRect()方法来帮助系统识别那些可见的区域。使用canvas.clipRect()方法可以指定一块矩形区域,只有在这个区域内的View才会被绘制,其他的区域的View都将被忽略。这种方法极大地避免了CPU与GPU资源的浪费。
下面是使用clipRect来解决自定义View Over Draw的例子,首先我们来看下原始方案的效果,在Over Draw 开启的情况下在层叠部分显示了大面积的红色区块,这是不可取的。
我们查看下该自定义View的onDraw方法:
代码逻辑很简单就是每隔一段偏移绘制一个图片。

下面是使用clipRect()方法来解决自定义View OverDraw问题的方案以及效果:


从效果上看红色区块已经完全去掉了。
打开手机Settings里面的开发者选项,选择Profile GPU Rendering,选中On screen as bars的选项。就可以在手机屏幕上看到GPU Rending信息。

随着界面的刷新,界面上会用实时滚动的垂直柱状图来表示每帧画面所需要渲染的时间,柱状图越高表示花费的渲染时间越长。
界面上使用一条绿线表示16ms,如果柱状图的某个项超过这条横线那么就有可能导致丢帧照成的卡顿现象的发生。
从Android M系统开始,系统对GPU Profiling 功能进行了增强,早期的CPU Profiling工具只能粗略的显示出Process,Execute,Update三大步骤的时间耗费情况。下面是对应的视图情况。
在Android M版本开始,GPU Profiling工具把渲染操作拆解成如下8个阶段:
旧版本中提到的Proces,Execute,Update还是继续得到了保留,他们的对应关系如下:
接下去我们看下其他五个步骤分别代表了什么含义:
Swap Buffers 对应的是之前的Process阶段,表示渲染引擎执行显示列表所花的时间,view越多,时间就越长。
Command Issue对应的是之前的Execute阶段,表示把一帧数据发送到屏幕上排版显示实际花费的时间。其实是实际显示帧数据的后台缓存区与前台缓冲区交换后并将前台缓冲区的内容显示到屏幕上的时间。所以这个时间,一般都很短。
Draw 对应的是之前的Update阶段,表示在Java中创建显示列表部分中,OnDraw()方法占用的时间。
Sync & Upload:通常表示的是准备当前界面上有待绘制的图片所耗费的时间,为了减少该段区域的执行时间,我们可以减少屏幕上的图片数量或者是缩小图片本身的大小。
Measure & Layout:这里表示的是布局的onMeasure与onLayout所花费的时间,一旦时间过长,就需要仔细检查自己的布局是不是存在严重的性能问题。
Animation:表示的是计算执行动画所需要花费的时间,包含的动画有 ObjectAnimator,ViewPropertyAnimator,Transition等等。一旦这里的执行时间过长,就需要检查是不是使用了 非官方的动画工具或者是检查动画执行的过程中是不是触发了读写操作等等。
Input Handling:表示的是系统处理输入事件所耗费的时间,粗略等于对于的事件处理方法所执行的时间。一旦执行时间过长,意味着在处理用户的输入事件的地方执行了复杂的操作。
Misc/Vsync Delay:如果稍加注意,我们可以在开发应用的Log日志里面看到这样一行提 示:I/Choreographer(691): Skipped XXX frames! The application may be doing too much work on its main thread。这意味着我们在主线程执行了太多的任务,导致UI渲染跟不上vSync的信号而出现掉帧的情况。
Hierarchy 工具位于sdk的tool目录下,如果你使用的是Android Studio的话需要点击Android Device Monitor 工具进入。插入手机后会在左边的面板上会显示各个Activity的名字,点击要测试的Activity的名称就可以进入这个Activity的层级视图树。
通过这个视图树可以很明显得看出整个页面布局的视图结构,一般理想的布局的视图树是扁平的。
Save as PNG用来把当前视图树保存为一张png图片
Capture Layers用来分层保存
Load View Hierarchy用来手动刷新变化
Profile Node:用于触发测试。获取某个节点View的个数,Measure,Layout,Draw各个步骤所消耗的时间。这里通过红,黄,绿三种不同的颜色来区分布局的Measure,Layout,Executive的相对性能表现
右侧显示选中View的当前属性状态
右下角以红色框的形式显示当前View在Activity中的位置
其他的按钮也是很常见的大家可以自己探索下。
我们重点看下每个节点的视图信息部分:
在上面提到了点击Profile Node会触发测试,点击某个节点将会出现如下界面:
上图最底那三个彩色灯代表了当前View的性能指标,从左到右依次代表测量、布局、绘制的渲 染时间,红色和黄色的点代表速度渲染较慢的View
在自定义View的性能调试时,HierarchyViewer上面的invalidate Layout和requestLayout两个功能十分有帮助,我们可以在我们自定义View的代码上打上断点使用这两个按钮就可以执行invalidate()和 requestLayout()过程。

