Java 进阶系列之IO
本章知识点
Java提供了三种内建注解。
@Override |
Java中提供了四种元注释用于定义自定义注释,如下所示:
@Target 表示该注解可以用在什么地方,由ElementType枚举定义 ,当注解未指定Target值时,该注解可以使用任何元素之上
PACKAGE:包声明 |
@Retention 表示需要在什么级别保存该注解信息,由RetentionPolicy枚举定义,当注解未定义Retention值时,默认值是CLASS
SOURCE:注解将被编译器丢弃(该类型的注解信息只会保留在源码里,源码经过编译后,注解信息会被丢弃,不会保留在编译好的class文件里) |
@Documented 表示注解会被包含在javaApi文档中
@Inherited 允许子类继承父类的注解,表示注解类型能被自动继承。 如果一个类使用了 @Inherited 类型的注解,则此类的子类也将含有该注解。
import java.lang.annotation.*; |
需要注意的是注解也将会编译成class文件,我们通过javac将上述的注解编译为字节码,然后使用javap对其进行反编译,将会得到如下的代码:
public interface AnatationTest extends java.lang.annotation.Annotation { |
也就是说使用@interface 关键字声明一个注解,它会自动继承 java.lang.annotation.Annotaion 接口。
自定义注解的时候需要注意如下几点:
所有基本类型(int,float,boolean,byte,double,char,long,short) |
注释的解析有两种方式:
下面是运行时解析的例子:
|
(desc = "This is TypeAnnotation") |
package-info.java
|
public class RuntimeAnnotationProcessor { |
编译时解析
编译时注解指的是@Retention的值为CLASS的注解。对于这类注解的解析,我们需要自定义一个派生自 AbstractProcessor的“注解处理类”并重写process 函数。
APT(Annotation Processing Tool)是一种处理注释的工具
Annotation处理器在处理注释时可以根据源文件中的Annotation生成额外的源文件和其它的文件,APT还会编译生成的源文件和原来的源文件,将它们一起生成class文件。
整个注解处理器的可以由如下几个部分构成:
注解处理器(AbstractProcess)+代码处理(JavaPoet)+处理器注册(AutoService)+apt
整个过程分成如下几个部分:
1.定义注解(如@automain)
2.定义注解处理器
3.在处理器里面完成处理方式,通常是生成java代码,这个就需要用到代码处理。
4.注册处理器,这里就需要用到处理器注册。
5.利用APT进一步处理。
建立一个APT 项目,并添加apt依赖:
buildscript { |
添加apt 插件
//添加APT plugin |
新建一个model 命名为compiler 用于存放注解处理器:
并添加autoservice 和javapoet依赖:
apply plugin: 'java' |
创建AnnotationProcessor
package com.example; |
这时候编译后会在/app/build/generated/source/apt/debug/目录下生成HelloWorld.java文件
参考材料
http://www.race604.com/annotation-processing/
http://www.jianshu.com/p/1942ad208927
http://blog.csdn.net/lmj623565791/article/details/43452969
https://github.com/taoweiji/DemoAPT?utm_source=tuicool&utm_medium=referral
http://www.cnblogs.com/lbangel/p/3523741.html
http://www.jianshu.com/p/94979c056b20
http://alighters.com/blog/2016/05/10/apt-code-generate/
本章知识点
在开始介绍今天的专题之前我们首先需要明确下什么时候我们会使用到枚举,在未接触枚举之前,大家或许写过这样的代码:
public static final int LIGHT_STATUS_OFF = 1; //表示灯关闭的状态 |
也就是用一些常量表示某个时刻的状态,这种表示方式有如下几个缺点:
为了解决这些问题在5.0 版本 SDK 发布时候引入了枚举特性,通过枚举,可以把相关的常量分组到一个枚举类型里,而且枚举提供了比常量更多的方法。
上面的常量可以通过下面的枚举变量进行实现:
public enume LIGHT_STATUS { |
Enume 对象的可用方法不多,列举如下:
values() 用于返回整个枚举所包含的状态值 |
private enum LIGHT_STATUS { |
由于编译器会自动为我们提供equals()以及hashCode(),所以可以使用==来比较enume实例,同时由于它也实现了Comparable接口所以也可以使用compareTo方法进行比较,除了实现了Comparable 接口外,它还实现了Serializable接口。
public void enumeValueCompare() { |
枚举的定义和类的定义十分相似,但是也存在着一些区别,下面是二者的区别点:
下面是自定义的一个枚举类型:
private enum ITEM_TYPE { |
它包括每个枚举类型实例,以及枚举类型的描述,下面是测试例子:
上面的例子中我们通过声明抽象方法,在每个enume 实例中进行覆写,来指定每个enume实例相关的方法,而在实例声明之后的方法实现的是全部实例共有的方法。
public void customEnume() { |
我们看sdk源码的时候可以发现enume实际上是继承自Enume类的,但是Enume 类中并没有values方法,实际上values是编译器添加的静态方法,所以如果我们将enume实例向上转型为Enum 那么 values方法就不可使用了。
解决这个问题我们可以借助Class类中的getEnumeConstants 方法来获取所有enume实例。
public void getEnumeConstants() { |
有时候我们每个枚举实例中还包含其他分类,这时候就要讲究枚举类的分类了:
下面是一种比较标准的分类写法,它使用接口Food将不同的子类组织起来,再通过getEnumConstants
获取每种子类型的值:
private enum FOOD { |
EnumeSet用法:
在刚接触枚举的时候,当时没有觉得它有什么用处,第一感觉它和枚举没啥区别。但是后面才发现二者的区别,传统的enume不能添加或者删除元素,但是EnumeSet 可以添加删除。
假设我们有一种情况下,某个版本有不同的特性,这些特性分别用枚举实例来表示。那么这时候我们就可以构造一个具有全部特性的EnumeSet 再根据版本号来将代表某写特性的枚举值添加或者移除:
public void testEnumeSet() { |
EnumeMap用法:
public void testEnumeMap() { |
在使用 Enum 时候有几个地方需要注意:
enum 类型不支持 public 和 protected 修饰符的构造方法,因此构造函数一定要是 private。也正因为如此,所以枚举对象是无法在程序中通过直接调用其构造方法来初始化的。
定义 enum 类型时候,如果是简单类型,那么最后一个枚举值后不用跟任何一个符号;但如果有定制方法,那么最后一个枚举值与后面代码要用分号’;’隔开,不能用逗号或空格。
由于 enum 类型的值实际上是通过运行期构造出对象来表示的,所以在 cluster 环境下,每个虚拟机都会构造出一个同义的枚举对象。因而在做比较操作时候就需要注意,如果直接通过使用等号 ( ‘ == ’ ) 操作符,这些看似一样的枚举值一定不相等,因为这不是同一个对象实例。
一个 Java 源文件中最多只能有一个 public 类型的枚举类,且该 Java 源文件的名字也必须和该枚举类的类名相同
使用 enum 定义的枚举类默认继承了 java.lang.Enum 类,并实现了 java.lang.Seriablizable 和 java.lang.Comparable 两个接口;
枚举类的所有实例(枚举值)必须在枚举类的第一行显式地列出,否则这个枚举类将永远不能产生实例。列出这些实例(枚举值)时,系统会自动添加 public static final 修饰,无需显式添加。
(该部分引用自 http://www.codeceo.com/article/why-android-not-use-enums.html)
关于Android性能优化中一个常见的建议是不要在你的代码中使用Enums,就连 Android官网上都强烈建议不要使用。为什么?
因为使用枚举之后增加了dex包的大小,理论上dex包越大,加载速度越慢
同时使用枚举,运行时的内存占用也会相对变大 (Enums often require more than twice as much memory as static constants)
Android中当你的App启动后系统会给App单独分配一块内存。App的DEX code、Heap以及运行时的内存分配都会在这块内存中。接下来看两种写法:
public static final int VALUE1 =1; |
public static enum Value{ |
public final class VALUE extends java.lang.Enum{ |
http://stackoverflow.com/questions/29183904/should-i-strictly-avoid-using-enums-on-android
大体的意思是,在如下情况下可以考虑用枚举
除了这些情况大家尽量不使用枚举,简单来说就是能不用enume 的尽量不用,那么我们是否能够克服使用静态常量的问题呢?肯定是有办法的,下面就介绍下Android中的替代方案:
public class Sexs { |
public class MainActivity extends Activity { |
@SEX注解可以放到属性定义,参数,返回值等地方对数据类型进行限制。
为了说明这个问题我们先编写一个枚举类如下所示:
public enum EnumeTest { |
然后紧接着将该类编译成class文件,然后使用javap来反编译查看到底长啥样,下面就是反编译后的样子:
public final class EnumeTest extends java.lang.Enum<EnumeTest> { |
大家应该知道为什么enume后面不能使用extends来继承其他类了吧,因为已经继承了Enum,Java中不支持多继承,那为啥不能被其他继承?因为是final 类。
混淆大家估计都懂吧,即使不懂也听说过这个概念,就是用于增强反编译的难度,基本上大多数的app在发布之前都会通过混淆处理,在默认的混淆配置文件中,已经加入了对枚举混淆的处理
# For enumeration classes, see http://proguard.sourceforge.net/manual/examples.html#enumerations |
使用Proguard进行优化,可以将枚举尽可能的转换成int。配置如下
-optimizations class/unboxing/enum |
确保上述代码生效,需要确proguard配置文件不包含-dontoptimize指令。
http://www.ibm.com/developerworks/cn/java/j-lo-enum/
https://www.liaohuqiu.net/cn/posts/android-enum-memory-usage/
http://www.cnblogs.com/zgz345/p/5871351.html
http://stackoverflow.com/questions/29183904/should-i-strictly-avoid-using-enums-on-android
http://droidyue.com/blog/2016/11/29/dive-into-enum/index.html
http://www.jianshu.com/p/f8ac84a3e3c1
变量名可以使用$或者 _开头
javascript 有七种数据类型:Number , String ,Boolean, Object,null,undefined,symbol.
由于JavaScript的变量作用域实际上是函数内部,我们在for循环等语句块中是无法定义具有局部作用域的变量的:
; |
为了解决块级作用域,ES6引入了新的关键字let,用let替代var可以申明一个块级作用域的变量:
; |
由于var和let申明的是变量,如果要申明一个常量,在ES6之前是不行的,我们通常用全部大写的变量来表示“这是一个常量,不要修改它的值”:
var PI = 3.14; |
ES6标准引入了新的关键字const来定义常量,const与let都具有块级作用域:
; |
使用var申明的变量则不是全局变量,它的范围被限制在该变量被申明的函数体内,同名变量在不同的函数体内互不冲突。
为了修补JavaScript这一严重设计缺陷,ECMA在后续规范中推出了strict模式,在strict模式下运行的JavaScript代码,强制通过var申明变量,未使用var申明变量就使用的,将导致运行错误。启用strict模式的方法是在JavaScript代码的第一行写上:
; |
这是一个字符串,不支持strict模式的浏览器会把它当做一个字符串语句执行,支持strict模式的浏览器将开启strict模式运行JavaScript。
JavaScript在设计之初,为了方便初学者学习,并不强制要求用var申明变量。这个设计错误带来了严重的后果:如果一个变量没有通过var申明就被使用,那么该变量就自动被申明为全局变量:
i = 10; // i现在是全局变量
定义值的标志有三种 var let const:
null 和undefined的区别:
JavaScript的设计者希望用null表示一个空的值,而undefined表示值未定义。事实证明,这并没有什么卵用,区分两者的意义不大。大多数情况下,我们都应该用null。undefined仅仅在判断函数参数是否传递的情况下有用。实际上也可以记住,对象类型用null。基本数据类型用undefined。
关于字符串
‘’单引号可以包含双引号,双引号内部可以包含单引号,· · 内部可以包含很多包括换行在内的符号由于多行字符串用\n写起来比较费事,所以最新的ES6标准新增了一种多行字符串的表示方法,用...表示:这是一个 多行 字符串;
要把多个字符串连接起来,可以用+号连接:
var name = '小明'; |
如果有很多变量需要连接,用+号就比较麻烦。ES6新增了一种模板字符串,表示方法和上面的多行字符串一样,但是它会自动替换字符串中的变量:
var name = '小明'; |
要特别注意相等运算符==。JavaScript在设计时,有两种比较运算符:
第一种是==比较,它会自动转换数据类型再比较,很多时候,会得到非常诡异的结果;
第二种是===比较,它不会自动转换数据类型,如果数据类型不一致,返回false,如果一致,再比较。
由于JavaScript这个设计缺陷,不要使用==比较,始终坚持使用===比较。
还有一个特殊的对比符号为全不等,表示数值和类型都不相等。
&& 和|| 返回的是第一个可以判断结果的那个值
for in
for循环的一个变体是for … in循环,它可以把一个对象的所有属性依次循环出来:
var o = { |
由于Array也是对象,而它的每个元素的索引被视为对象的属性,因此,for … in循环可以直接循环出Array的索引:
var a = ['A', 'B', 'C']; |
for of 与for in的区别
for … in循环由于历史遗留问题,它遍历的实际上是对象的属性名称。一个Array数组实际上也是一个对象,它的每个元素的索引被视为一个属性。当我们手动给Array对象添加了额外的属性后,for … in循环将带来意想不到的意外效果:
var a = ['A', 'B', 'C']; |
for … in循环将把name包括在内,但Array的length属性却不包括在内。
for … of循环则完全修复了这些问题,它只循环集合本身的元素:
var a = ['A', 'B', 'C']; |
这就是为什么要引入新的for … of循环。
NaN这个特殊的Number与所有其他值都不相等,包括它自己:
NaN === NaN; // false |
唯一能判断NaN的方法是通过isNaN()函数:
isNaN(NaN); // true |
数组:
[1, 2, 3.14, 'Hello', null, true]; |
可以是任意元素
可以读和修改某个元素
要取得Array的长度,直接访问length属性:
var arr = [1, 2, 3.14, 'Hello', null, true]; |
请注意,直接给Array的length赋一个新的值会导致Array大小的变化:
var arr = [1, 2, 3]; |
Array可以通过索引把对应的元素修改为新的值,因此,对Array的索引进行赋值会直接修改这个Array:
var arr = ['A', 'B', 'C']; |
请注意,如果通过索引赋值时,索引超过了范围,同样会引起Array大小的变化:
var arr = [1, 2, 3]; |
大多数其他编程语言不允许直接改变数组的大小,越界访问索引会报错。然而,JavaScript的Array却不会有任何错误。在编写代码时,不建议直接修改Array的大小,访问索引时要确保索引不会越界。
函数
参数类
JavaScript的函数在查找变量时从自身函数定义开始,从“内”向“外”查找。如果内部函数定义了与外部函数重名的变量,则内部函数的变量将“屏蔽”外部函数的变量。
参数个数判断
如果没有return语句,函数执行完毕后也会返回结果,只是结果为undefined。
由于JavaScript允许传入任意个参数而不影响调用,因此传入的参数比定义的参数多也没有问题,虽然函数内部并不需要这些参数:
传入的参数比定义的少也没有问题。
arguments
JavaScript还有一个免费赠送的关键字arguments,它只在函数内部起作用,并且永远指向当前函数的调用者传入的所有参数。arguments类似Array但它不是一个Array:
function foo(x) { |
利用arguments,你可以获得调用者传入的所有参数。也就是说,即使函数不定义任何参数,还是可以拿到参数的值:
function abs() {if (arguments.length === 0) { |
实际上arguments最常用于判断传入参数的个数。你可能会看到这样的写法:
// foo(a[, b], c)// 接收2~3个参数,b是可选参数,如果只传2个参数,b默认为null:function foo(a, b, c) {if (arguments.length === 2) { |
要把中间的参数b变为“可选”参数,就只能通过arguments判断,然后重新调整参数并赋值。
rest参数
由于JavaScript函数允许接收任意个参数,于是我们就不得不用arguments来获取所有参数:
function foo(a, b) {var i, rest = []; |
为了获取除了已定义参数a、b之外的参数,我们不得不用arguments,并且循环要从索引2开始以便排除前两个参数,这种写法很别扭,只是为了获得额外的rest参数,有没有更好的方法?
ES6标准引入了rest参数,上面的函数可以改写为:
function foo(a, b, ...rest) { |
rest参数只能写在最后,前面用…标识,从运行结果可知,传入的参数先绑定a、b,多余的参数以数组形式交给变量rest,所以,不再需要arguments我们就获取了全部参数。
如果传入的参数连正常定义的参数都没填满,也不要紧,rest参数会接收一个空数组(注意不是undefined
由于JavaScript的函数可以嵌套,此时,内部函数可以访问外部函数定义的变量,反过来则不行:
; |
名字空间
全局变量会绑定到window上,不同的JavaScript文件如果使用了相同的全局变量,或者定义了相同名字的顶层函数,都会造成命名冲突,并且很难被发现。
减少冲突的一个方法是把自己的所有变量和函数全部绑定到一个全局变量中。例如:
// 唯一的全局变量MYAPP:var MYAPP = {}; |
把自己的代码全部放入唯一的名字空间MYAPP中,会大大减少全局变量冲突的可能。
全局作用域
不在任何函数内定义的变量就具有全局作用域。实际上,JavaScript默认有一个全局对象window,全局作用域的变量实际上被绑定到window的一个属性:
; |
因此,直接访问全局变量course和访问window.course是完全一样的。
你可能猜到了,由于函数定义有两种方式,以变量方式var foo = function () {}定义的函数实际上也是一个全局变量,因此,顶层函数的定义也被视为一个全局变量,并绑定到window对象:
; |
名称空间
全局作用域
局部作用域
参数作用域
对象
访问属性是通过.操作符完成的,但这要求属性名必须是一个有效的变量名。如果属性名包含特殊字符,就必须用’’括起来:
访问这个属性也无法使用.操作符,必须用[‘xxx’]来访问:
如果我们要检测xiaoming是否拥有某一属性,可以用in操作符:
要判断一个属性是否是xiaoming自身拥有的,而不是继承得到的,可以用hasOwnProperty()方法:
'name' in xiaoming; // true |
JavaScript对每个创建的对象都会设置一个原型,指向它的原型对象。
当我们用obj.xxx访问一个对象的属性时,JavaScript引擎先在当前对象上查找该属性,如果没有找到,就到其原型对象上找,如果还没有找到,就一直上溯到Object.prototype对象,最后,如果还没有找到,就只能返回undefined。
var myObject = { |
使用apply和call来绑定this的指向
虽然在一个独立的函数调用中,根据是否是strict模式,this指向undefined或window,不过,我们还是可以控制this的指向的!
要指定函数的this指向哪个对象,可以用函数本身的apply方法,它接收两个参数,第一个参数就是需要绑定的this变量,第二个参数是Array,表示函数本身的参数。
用apply修复getAge()调用:
function getAge() {var y = new Date().getFullYear(); |
apply()把参数打包成Array再传入;
call()把参数按顺序传入。
比如调用Math.max(3, 5, 4),分别用apply()和call()实现如下:
Math.max.apply(null, [3, 5, 4]); // 5 |
对普通函数调用,我们通常把this绑定为null。
装饰器:
利用apply(),我们还可以动态改变函数的行为。
JavaScript的所有对象都是动态的,即使内置的函数,我们也可以重新指向新的函数。
现在假定我们想统计一下代码一共调用了多少次parseInt(),可以把所有的调用都找出来,然后手动加上count += 1,不过这样做太傻了。最佳方案是用我们自己的函数替换掉默认的parseInt():
var count = 0; |
另一个需要注意的问题是,返回的函数并没有立刻执行,而是直到调用了f()才执行。我们来看一个例子:
返回闭包时牢记的一点就是:返回函数不要引用任何循环变量,或者后续会发生变化的变量。
闭包(closure)是Javascript语言的一个难点,也是它的特色,很多高级应用都要依靠闭包实现。 |
箭头函数: 用箭头定义函数……..
var fun = x=>x*x |
箭头函数有两种格式,一种像上面的,只包含一个表达式,连{ … }和return都省略掉了。还有一种可以包含多条语句,这时候就不能省略{ … }和return:
箭头函数和匿名函数一个明显的区别是this指针。箭头函数中的this指针由上下文决定。
在函数中定义函数
将函数作为参数
将函数作为返回值
compile 'io.reactivex:rxjava:1.1.0' //RxJava 相关 |
public interface OpenWeatherApi { |
( 1 ) GET 请求方式:
public interface GitHubService {//无参数@GET("users/stven0king/repos") |
( 2 ) POST 请求方式:
public interface GitHubService {//无参数@POST("users/stven0king/repos") |
@POST @GET多了一个@FromUrlEncoded的注解。如果去掉@FromUrlEncoded在post请求中使用@Field和@FieldMap,那么程序会抛出Java.lang.IllegalArgumentException: @Field parameters can only be used with form encoding. (parameter #1)的错误异常。
( 3 ) 半静态的url 地址请求:
public interface GitHubService {@GET("users/{user}/repos") |
( 4 ) 动态的url地址请求:
public interface GitHubService {@GET |
Retrofit retrofit = new Retrofit.Builder() |
Gson: com.squareup.retrofit:converter-gson |
OpenWeatherApi mWeatherService = retrofit.create(OpenWeatherApi.class); |
Call<WeatherResult> resultCall = mWeatherService.getCityWeather("1790437","f8ddddd63c40c0bcb89"); |
resultCall.enqueue(new Callback<WeatherResult>() { |
new AsyncTask<String, Integer, Response<WeatherResult>>(){ |
call.cancel(); |
在Retrofit 1.9中,如果获取的 response 不能被解析成定义好的对象,则会调用failure。但是在Retrofit 2.0中,不管 response 是否能被解析。onResponse总是会被调用。但是在结果不能被解析的情况下,response.body()会返回null。
如果response存在什么问题,onResponse也会被调用。我们可以从response.errorBody().string()中获取错误信息的主体。
10 Retrofix 结合 Rxjava
public interface OpenWeatherApis { |
Retrofit retrofit = new Retrofit.Builder() |
OpenWeatherApis openWeatherApis = retrofit.create(OpenWeatherApis.class); |
11 添加log支持
HttpLoggingInterceptor httpLoggingInterceptor = new HttpLoggingInterceptor(); |
11 Retrofix 结合 Realm:
Realm 是我个人的喜好,是用得最爽的一个nosql类型的数据库,没有之一。
Realm 可以与 Retrofit 1.x 和 2.x 无缝配合工作。但注意 Retrofit 不会自动将对象存入 Realm。
需要通过调用 Realm.copyToRealm() 或 Realm.copyToRealmOrUpdate() 来将它们存入 Realm。
realm.beginTransaction(); |
今天开始我将对目前较为流行的开源库以及开源框架的源码进行分析,希望能够通过学习这些源码背后的设计思想,从而让自己的编程和设计能力有所提高。
废话不多说,切入正题。今天给大家介绍的picasso是一个图片缓存库,想必很多人对他都很熟悉了,它支持三级缓存,它的使用极为简单,同时也支持十分灵活的配置方式。大家可以通过如下地址下载到源码 http://square.github.io/picasso/
我们以一个最简单的使用情景来对源码进行分析:
Picasso.with(context).load("http://image.baidu.com/search/detail?z=0&ipn=").into(imageView); |
上面的代码是执行从网络上加载地址为http://image.baidu.com/search/detail?z=0&ipn= 的图片到指定的imageView控件中。
在分析源码之前我们先看下整个开源库的代码组织,但是大家如果将代码下载到本地后会感到失望,因为个人认为picasso的代码组织是极为不规范的,整个源码只有一个package。下面是我根据自己的理解将其源码进行重新的组织。总共分成5个包,
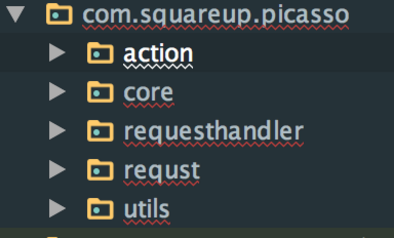
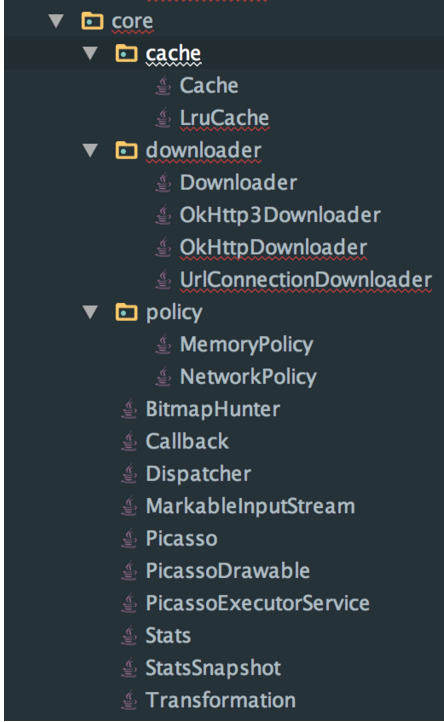
为什么这样分包大家可以在源码分析完后对整个流程以及每个类对职责有较为深入了解后进行思考。
3 .详细流程介绍
3.1 with 流程解析:
with阶段的主要任务是创建全局默认的Picasso实例,所创建的实例一般来说能够适合于绝大多数应用场景,如果不满足可以自己通过Builder来创建,也可以通过setSingletonInstance来注入我们自己创建的Picasso,但是这个方法需要在with方法前调用,因为这里创建picasso使用对是单例模式。
picasso默认对配置如下:
(1) 缓存使用LRU 缓存方式,缓存大小占用应用可用存储的15% RAM
(2) 硬盘缓存空间占用手机存储的2%,并且大小不小于5M,最大50MB。
(3) 具有3个线程用于磁盘和网络访问
(4) 缓存位于应用目录下对picasso-cache目录。
我们看下它是如何完成这部分的工作的,首先它使用建造者模式结合单例来创建picasso对象,之所以采用建造者模式是因为这种模式能够给配置参数多的对象的构建带来很大的方便。
public static Picasso with(@NonNull Context context) { |
我们能从Builder对象中获取到什么信息呢?一般一个对象的Builder是用于向外面暴露设置内部组件的接口(此接口非彼接口),通过暴露的接口来注入我们自定义的对象。Picasso 的 Builder也是一样的。通过它我们可以注入自定义的下载器,线程池,缓存,请求转换器,请求处理器,内部事件监听。它还有一个builder方法,它的用处就是在全部设置后,检查重要的组件是否有设置了,如果没有设置,那么就创建初始化组件来使用。
public static class Builder { |
接下来我们重点看下builder方法,如果我们没有注入自定义的下载器,那么就会调用createDefaultDownloader创建出一个下载器:
下面这种写法也是比较值得借鉴的。下面的create方法只是在应用缓存目录下创建一个picasso-cache的缓存目录。后续下载的图片都缓存在这个目录下。
/**
public static Downloader createDefaultDownloader(Context context) { |
public LruCache(@NonNull Context context) { |
根据是否是大堆栈类型,如果是则获取大堆栈存储,否则获取标准堆栈存储。然后使用大概15%的存储空间作为缓存。
static int calculateMemoryCacheSize(Context context) { |
接着我们看下默认的线程池的设置:
它是继承自ThreadPoolExcutor
class PicassoExecutorService extends ThreadPoolExecutor |
紧接着我们来看下请求转换器:
请求转换器会在每次请求被提交的时候被调用,它主要用于修改某个请求的信息。我们看到默认的请求,并没有对请求做任何事情,只是简单的将原先的请求返回。
public interface RequestTransformer { |
Picasso 还有一个统计对象States,用于统计Picasso中的各种事件。它的主要对象只有三个带有消息处理能力的HandlerThread线程,一个Cache引用,一个Handler。
final HandlerThread statsThread; |
整个流程如下所示:
外界通过State对象调用dispatchXXXX方法,在dispatch方法中往Handler中发送事件,然后再调用performXXXX来处理这个事件。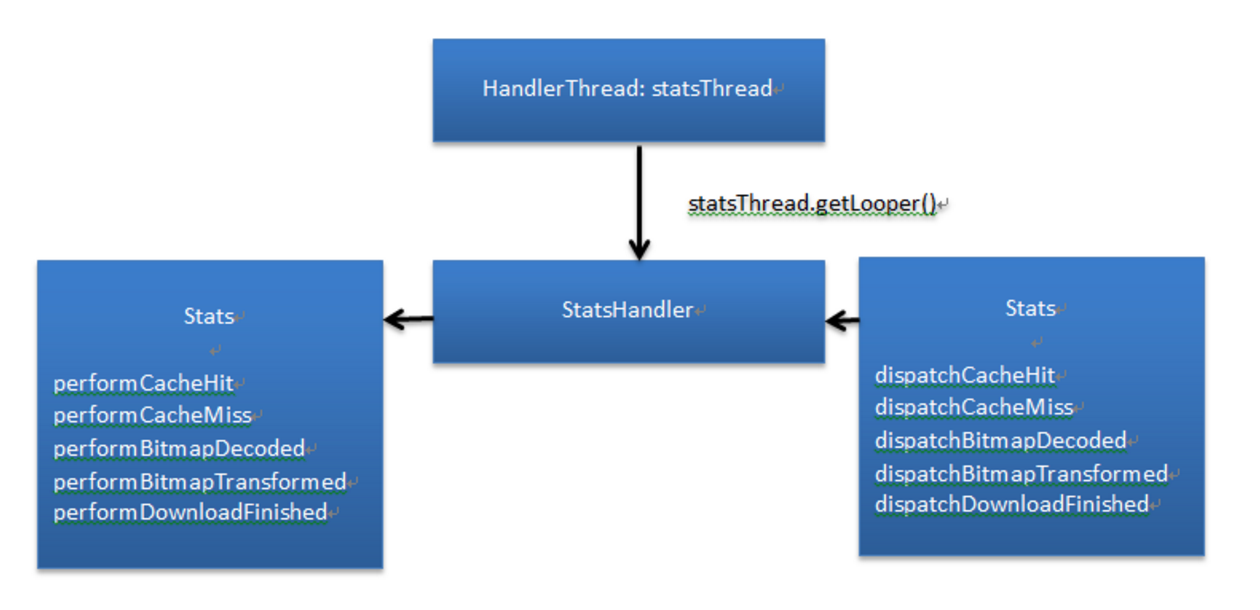
接下来我们继续看下Dispatcher,它负责分发Action的:
我们先看下她的构造方法:
Dispatcher(Context context, ExecutorService service, Handler mainThreadHandler, |
整个流程还是和State对象一致,也是由HandlerThread + Handler构成,外部调用dispatchXXX方法传递事件,在Handler中周转下最终调用performXXXX进行处理。这个具体涉及到的时候再重点介绍。
在build最后新建一个Picass对象返回,我们看下Picass对象的构造方法:
/**
Picasso(Context context, Dispatcher dispatcher, Cache cache, Listener listener, |
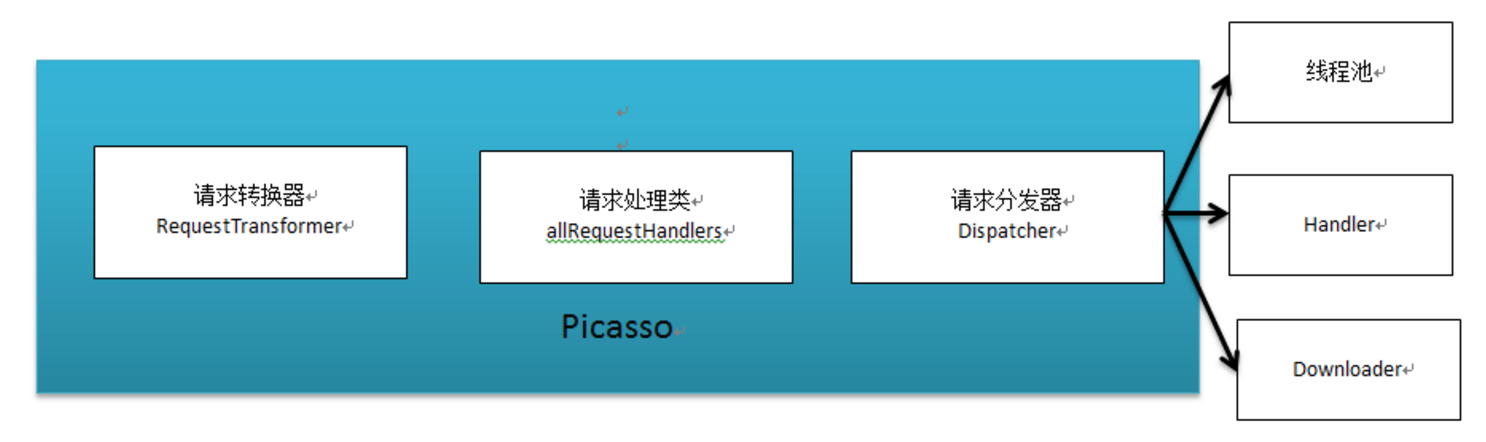
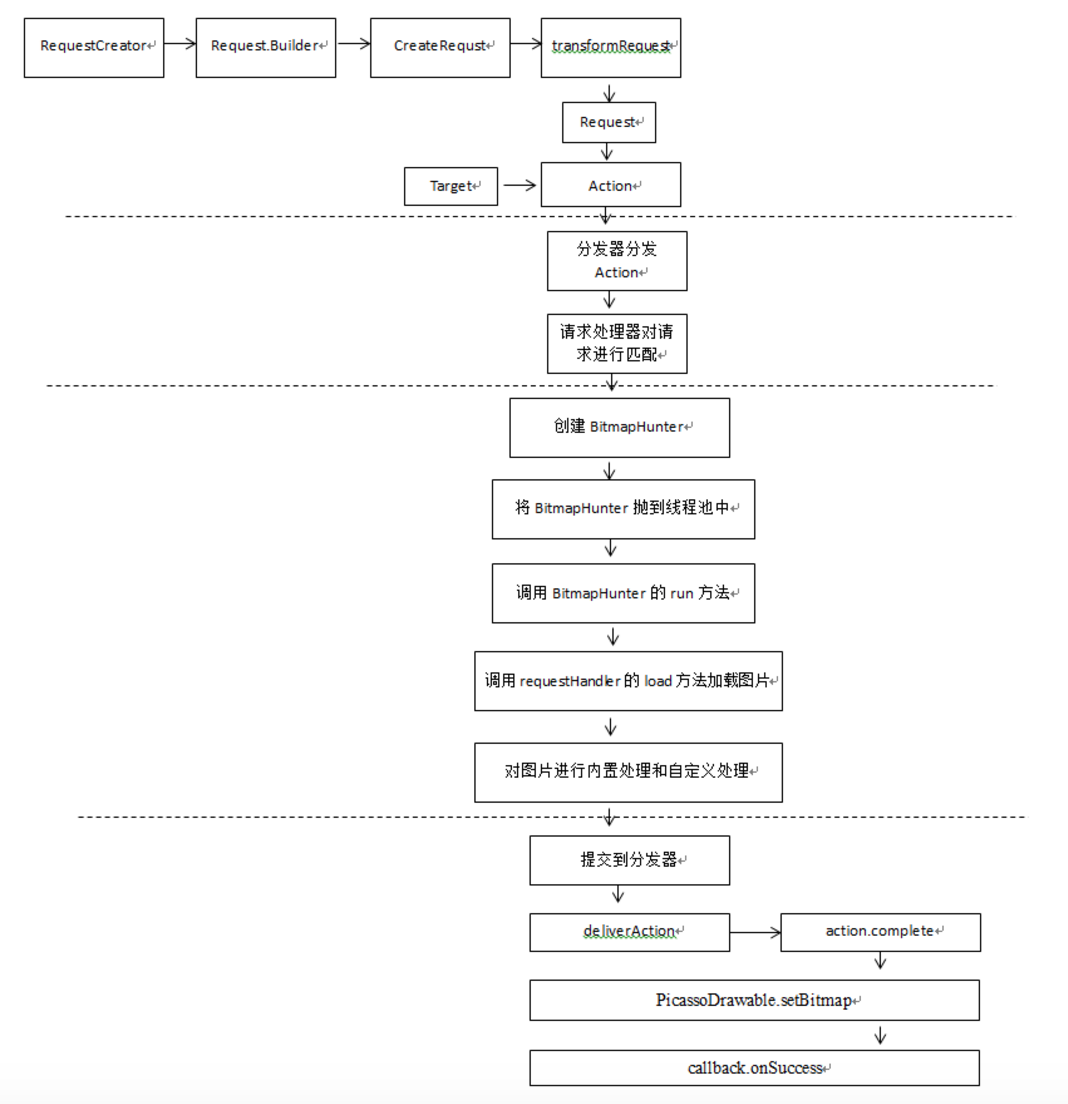
with流程总结:
在with阶段主要是使用建造模式和单例模式,创建Picasso对象。在通过Picasso的Builder接口我们可以看出Picasso可以允许我们注入自定义的下载器,线程池,缓存,请求转换器,请求处理器,内部事件监听。然后通过build方法中检查哪些对象还没创建,如果还没创建就使用默认的方案,在创建Picasso对象的阶段会注册系列的请求处理器为后续的请求处理做准备。
我们可以从这个部分学到什么?
3.2 load流程:
public RequestCreator load(@Nullable Uri uri) { |
在load阶段传递的是用于标示图片的Uri. path resourceId等。返回的是RequestCreator
RequestCreator(Picasso picasso, Uri uri, int resourceId) { |
这里实际上只是创建了一个Request.Builder为创建请求对象做准备。load阶段很简单吧。 这个阶段重点记住load提供的接口有如下几种:
public RequestCreator load(@Nullable Uri uri) |
load阶段总结:
load阶段就完成两个任务,一个是创建一个RequestCreator,另一个是创建Requst.Builder.为into阶段做准备。
3.3 into流程分析:
下面代码是整个流程的代码,每个步骤我们将会在后面一一展开。
public void into(ImageView target, Callback callback) { |
3.1.1 Request的创建过程
into阶段会先对传入的Uri进行判断,如果为空就取消请求。并根据需要决定是否显示占位符
然后使用load阶段创建的Request.Builder来创建请求。每个请求都有两个关键的成员,一个id一个创建时间。创建完Request对象后会通过请求转换器对其进行转换。
private Request createRequest(long started) { |
我们先来看下Request.Builder 的 build方法:
public Request build() { |
上述的build过程首先对参数进行检查,通过上述的Requst对象中注入了包括uri在内的众多参数。
紧接着就是根据request对象来生成用于标示Requst的RequestKey。
static String createKey(Request data, StringBuilder builder) { |
3.1.2 发起请求
( 1 ) 从缓存预取
在发起请求的时候首先查看下缓存策略,看下是否优先从缓存中获取图片数据,如果是的话就调用picasso.quickMemoryCacheCheck来检查缓存中是否已经有需要的数据了。如果有就返回,并且将结果传递给统计对象。然后取消现有的请求,并将图像设置到ImageView上。
Bitmap quickMemoryCacheCheck(String key) { |
(2) 创建Action 通过其他途径获取
紧接着创建一个ImageViewAction然后调用picasso.enqueueAndSubmit将Action发出。接下来这部分是非常重要的,所以在进行这部分介绍之前进行一下总结:
在into阶段首先会使用load阶段创建的RequstCreator来创建一个Request,并设置Requst的id以及启动时间这两个关键,参数,在创建Request这个过程中会先检查一系列的参数,然后再new出一个Requst对象出来。然后再使用创建出的Requst对象的参数创建出作为Request标示的requestKey。
再根据缓存策略,查看是否优先使用缓存中的图像,如果是的话那么就使用上面创建出来的requstKey从缓存中获取,并将结果反馈给stats对象进行统计,如果不优先使用缓存中的图像的话那么就创建出一个Action,然后调用picasso.enqueueAndSubmit将Action发出。
Action 是Target 以及Request的封装,它有个重要的方法abstract void complete(Bitmap result, Picasso.LoadedFrom from)在请求结束的时候会调用这个进行处理,这个后续会进行介绍,Action的子类目前有GetAction FetchAction TargetAction ImageViewAction RmoteViewAction这些。
我们继续看接下来的流程:
在提交到分发器之前需要先检查当前Action的对象是否绑定了另外的Action,如果是的话那么取消原先的请求,将当前的Action和Target放到targetToAction。然后提交到分发器上。
void enqueueAndSubmit(Action action) { |
分发器分发请求:
void submit(Action action) { |
void dispatchSubmit(Action action) { |
|
void performSubmit(Action action) { |
上面的流程在之前已经介绍了,由外部调用dispatchXXXX方法,然后传递给Hander,然后再由performXXXXX进行处理。
匹配requestHandler封装到BitmapHunter:
在performSubmit中根据Action来判断那个requstHandler可以处理这个请求,然后将这个requstHandler传递到新创建的BitmapHunter中。
void performSubmit(Action action, boolean dismissFailed) { |
forRequst 方法中取出请求,以及请求处理器列表。依次调用请求处理器的canHandleRequst来判断当前requstHandler是否能够处理当前的请求。
static BitmapHunter forRequest(Picasso picasso, Dispatcher dispatcher, Cache cache, Stats stats, Action action) { |
每个requestHandler都有一个canHandleRequst的方法,将request进去,在这个方法中将根据请求的Uri来进行匹配。当前是否可以处理这个类型的请求。所以在new Picasso 对象的时候各个requestHandler的请求对象的添加顺序很关键。
下面是网络请求处理器的canHandleRequest的实现。
public boolean canHandleRequest(Request data) { |
在添加到线程池后将会调用BitmapHunter的run方法。在run方法中主要是获取最终的Bitmap,然后再通过分发器来返回结果。
public void run() { |
通过requestHandler中的load方法加载图片数据:
获取图片主要是通过hunt方法,在这个方法中会先尝试从缓存中获取,如果缓存中没有,那么通过requstHandler中的load方法,这时候会有两种可能,一种是直接返回Bitmap。另一种是返回一个InputStream。如果是Bitmap那么就直接进入下一步,如果是输入流的话需要将从流中对其进行解码。
Bitmap hunt() throws IOException { |
public Result load(Request request, int networkPolicy) throws IOException { |
图像执行内部以及自定义变换处理:
获取到Bitmap数据之后接着就进行图像的转换,首先进行内部的转换,这个是通过调用transformRequst进行的。
static Bitmap transformResult(Request data, Bitmap result, int exifOrientation) { |
接下来就是进行自定义的处理,这个是我们可以进行自己设置的。
static Bitmap applyCustomTransformations(List<Transformation> transformations, Bitmap result) { |
往主线程中返回处理后的Bitmap:
void dispatchComplete(BitmapHunter hunter) { |
case HUNTER_COMPLETE: { |
void performComplete(BitmapHunter hunter) { |
private void batch(BitmapHunter hunter) { |
case HUNTER_DELAY_NEXT_BATCH: { |
这里将上面的BitmapHandler数组返回给主线程。
void performBatchComplete() { |
显示图片处理:
在complete阶段每个BitmapHunter都会将自己传递给Picasso complete中进行处理。
case HUNTER_BATCH_COMPLETE: { |
在Picasso的complete方法中将会从BitmapHunter中获取到图片数据。通过deliverAction进行图片的显示。
void complete(BitmapHunter hunter) { |
在deliverAction中将会调用Action中的complete方法进行将图像显示到控件上。
private void deliverAction(Bitmap result, LoadedFrom from, Action action) { |
最终是调用PicassoDrawable的setBitmap方法显示到ImageView上的。
public void complete(Bitmap result, Picasso.LoadedFrom from) { |
static void setBitmap(ImageView target, Context context, Bitmap bitmap, |
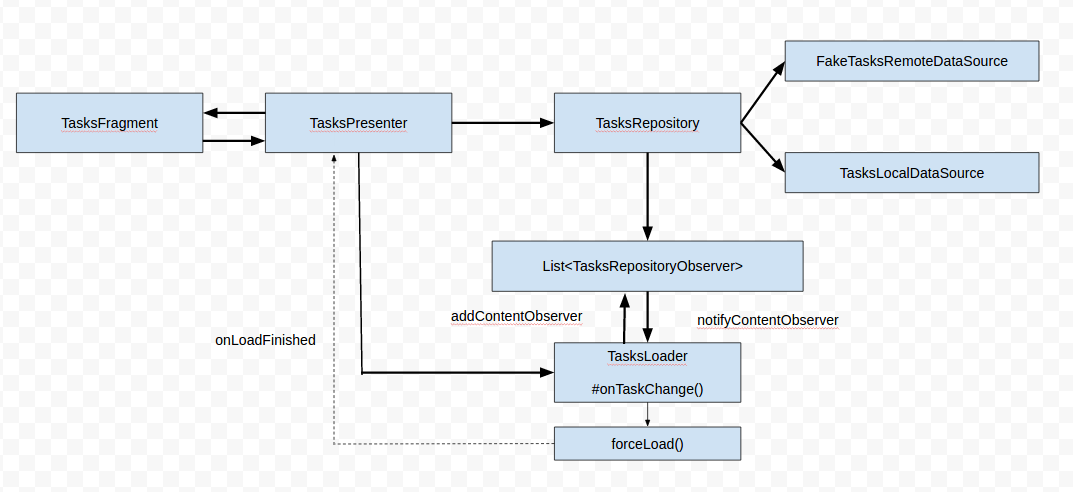
整个流程大致如下:
在看这篇博客之前请先看下Android 源码分析之TODO MVP 以及Android 进阶之设计模式 二 MVP模式。整个代码的流程在Android 源码分析之TODO MVP已经介绍过了,这篇博客将只介绍差异的部分。
还是老样子从TasksActivity开始分析:
public class TasksActivity extends AppCompatActivity { |
由于这个部分只是数据加载方式做了修改,所以View层TasksFragment没有多大的改变。 我们来看下数据层的代码:
public class TasksRepository implements TasksDataSource { |
从上面代码来看其实TasksRepository 主要的变化不大,主要是将原先的Callback回调变成了观察者模式。TasksLocalDataSource,以及TasksRemoteDataSource变化也不大。最大的变化应当属于TasksLoader
它是继承自AsyncTaskLoader以及实现了TasksRepositoryObserver。AsyncTaskLoader 这个之前都没介绍过,这个将会在后续的博客中补上。
一提到AsyncTaskLoader估计就会想到CursorLoader以及AysncTask,其实也差不多,它就是用于在后台中加载数据的。
public class TasksLoader extends AsyncTaskLoader<List<Task>> |
public class TasksPresenter implements TasksContract.Presenter, |
我们返过头看下,整个代码和之前的差别不是很大,差别主要是增加了TasksLoader,将原先在主要线程加载数据改成使用Loader在后台加载数据,并且使用Observer来监听数据集合的变化,来代替回调的方式。
下面是整个代码的结构: